May 1, 2021
It is not easy to finish the whole article in less than 15 minutes. I like to highlight some key points and work on my reading skills.
Here is the article.
Embracing the Differences : Inside the Netflix API Redesign
As I discussed in my recent blog post on ProgrammableWeb.com, Netflix has found substantial limitations in the traditional one-size-fits-all (OSFA) REST API approach. As a result, we have moved to a new, fully customizable API. The basis for our decision is that Netflix’s streaming service is available on more than 800 different device types, almost all of which receive their content from our private APIs. In our experience, we have realized that supporting these myriad device types with an OSFA API, while successful, is not optimal for the API team, the UI teams or Netflix streaming customers. And given that the key audiences for the API are a small group of known developers to which the API team is very close (i.e., mostly internal Netflix UI development teams), we have evolved our API into a platform for API development. Supporting this platform are a few key philosophies, each of which is instrumental in the design of our new system. These philosophies are as follows:
- Embrace the Differences of the Devices
- Separate Content Gathering from Content Formatting/Delivery
- Redefine the Border Between “Client” and “Server”
- Distribute Innovation
I will go into more detail below about each of these, including our implementation and what the benefits (and potential detriments) are of this approach. However, each philosophy reflects our top-level goal: to provide whatever is best for the Netflix customer. If we can improve the interaction between the API and our UIs, we have a better chance of making more of our customers happier.
Now, the philosophies…
Embrace the Differences of the Devices
The key driver for this redesigned API is the fact that there are a range of differences across the 800+ device types that we support. Most APIs (including the REST API that Netflix has been using since 2008) treat these devices the same, in a generic way, to make the server-side implementations more efficient. And there is good reason for this approach. Providing an OSFA API allows the API team to maintain a solid contract with a wide range of API consumers because the API team is setting the rules for everyone to follow.
While effective, the problem with the OSFA approach is that its emphasis is to make it convenient for the API provider, not the API consumer. Accordingly, OSFA is ignoring the differences of these devices; the differences that allow us to more optimally take advantage of the rich features offered on each. To give you an idea of these differences, devices may differ on:
- Memory capacity or processing power, potentially modifying how much content it can manage at a given time
- Requirements for distinct markup formats and broader device proliferation increases the likelihood of this
- Document models, some devices may perform better with flatter models, others with more hierarchical
- Screen real estate which may impact the content elements that are needed
- Document delivery, some performing better with bits streamed across HTTP rather than delivered as a complete document
- User interactions, which could influence the metadata fields, delivery method, interaction model, etc.
Our new model is designed to cut against the OSFA paradigm and embrace the differences across devices while supporting those differences equally. To achieve this, our API development platform allows each UI team to create customized endpoints. So the request/response model can be optimized for each team’s UIs to account for unique or divergent device requirements. To support the variability in our request/response model, we need a different kind of architecture, which takes us to the next philosophy…
Separate Content Gathering from Content Formatting/Delivery
In many OSFA implementations, the API is the engine that retrieves the content from the source(s), prepares that payload, and then ultimately delivers it. Historically, this implementation is also how the Netflix REST API has operated, which is loosely represented by the following image:
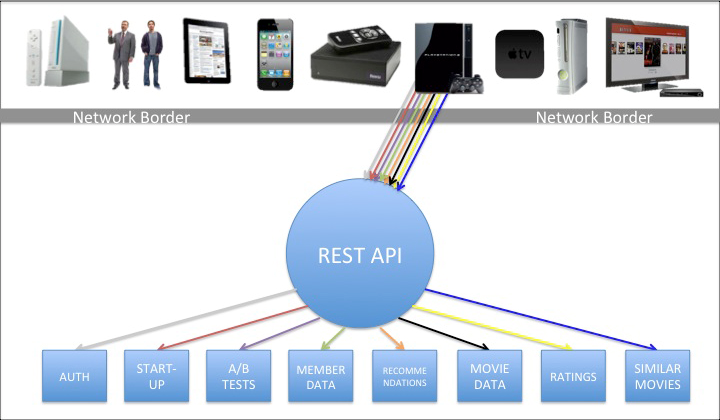
The above diagram shows a rainbow of colors roughly representing some of the different requests needed for the PS3, as an example, to start the Netflix experience. Other UIs will have a similar set of interactions against the OSFA REST API given that they are all required by the API to adhere to roughly the same set of rules. Inside the REST API is the engine that performs the gathering, preparation and delivery of the content (indifferent to which UI made the request).
Our new API has departed from the OSFA API model towards one that enables fine-grained customizations without compromising overall system manageability. To achieve this model, our new architecture clearly separates the operations of content gathering from content formatting and delivery. The following diagram represents this modified architecture:


In this new model, the UIs make a single request to a custom endpoint that is designed to specifically handle that request. Behind the endpoint is a handler that parses the request and calls the Java API, which gathers the content by calling back to a range of dependent services. We will discuss in later posts how we do this, particularly in how we parse the requests, trigger calls to dependencies, handle concurrency, support fallbacks, as well as other techniques we use to ensure optimized and accurate gathering of the content. For now, though, I will just say that the content gathering from the Java API is generic and independent of destination, just like the OSFA approach.
After the content has been gathered, however, it is handed off to the formatting and delivery engines which sit on top of the Java API on the server. The diagram represents this layer by showing an array of different devices resting on top of the Java API, each of which corresponds to the custom endpoints for a given UI and/or set of devices. The custom endpoints, as mentioned earlier, support optimized request/response handling for that device, which takes us to the next philosophy…
Redefine the Border Between “Client” and “Server”
The traditional definition of “client code” is all code that lives on a given device or UI. “Server code” is typically defined as the code that resides on the server. The divide between the two is the network border. This is often the case for REST APIs and that border is where the contract between the API provider and API consumer is engaged, as was the case for Netflix’s REST API, as shown below:


In our new approach, we are pushing this border back to the server, and with it goes a substantial portion of the UI-specific content processing. All of the code on the device is still considered client code, but some client code now resides on the server. In essence, the client code on the device makes a network call back to a dedicated client adapter that resides on the server behind the custom endpoint. Once back on the server, the adapter (currently written in Groovy) explodes that request out to a series of server-side calls that get the corresponding content (in some cases, roughly the same rainbow of requests that would be handled across HTTP in our old REST API). At that point, the Java APIs perform their content gathering functions and deliver the requested content back to the adapter. Once the adapter has some or all of its content, the adapter processes it for delivery, which includes pruning out unwanted fields, error handling and retries, formatting the response, and delivering the document header and body. All of this processing is custom to the specific UI. This new definition of client/server is represented in the following diagram:


There are two major aspects to this change. First, it allows for more efficient interactions between the device and the server since most calls that otherwise would be going across the network can be handled on the server. Of course, network calls are the most expensive part of the transaction, so reducing the number of network requests improves performance, in some cases by several seconds. The second key component leads us to the final (and perhaps most important) philosophy to this approach, which is the distribution of the work for building out the optimized adapters.
Distribute Innovation
One expected critique with this approach is that as we add more devices and build more UIs for A/B and multivariate tests, there will undoubtedly be myriad adapters needed to support all of these distinct request profiles. How can we innovate rapidly and support such a diverse (and growing) set of interactions? It is critical for us to support the custom adapters, but it is equally important for us to maintain a high rate of innovation across these UIs and devices.
As described above, pushing some of the client code back to the servers and providing custom endpoints gives us the opportunity to distribute the API development to the UI teams. We are able to do this because the consumers of this private API are the Netflix UI and device teams. Given that the UI teams can create and modify their own adapter code (potentially without any intervention or involvement from the API team), they can be much more nimble in their development. In other words, as long as the content is available in the Java API, the UI teams can change the code that lives on the device to support the user experience and at the same time change the adapter code to deliver the payload needed for that experience. They are no longer bound by server teams dictating the rules and/or being a bottleneck for their development. API innovation is now in the hands of the UI teams! Moreover, because these adapters are isolated from each other, this approach also diminishes the risk of harming other device implementations with tactical changes in their device-specific APIs.
Of course, one drawback to this is that UI teams are often more skilled in technologies like HTML5, CSS3, JavaScript, etc. In this system, they now need to learn server-side technologies and techniques. So far, however, this has been a relatively small issue, especially since our engineering culture is to hire very strong, senior-level engineers who are adaptable, curious and passionate about learning and implementing these kinds of solutions. Another concern is that because the UI teams are implementing server-side adapters, they have the potential to bring down the servers through infinite loops or other processes that are resource intensive. To offset this, we are working on scrubbing engines that will hopefully minimize the likelihood of such mistakes. That said, in the OSFA world, code on the device can just as easily DDOS the server, it is just potentially a bigger problem if it runs on the server.
Example of how this new system works:
- A device, such as the PS3, makes a single request across the network to load the home screen (This code is written and supported by the PS3 UI team.
- A Groovy adapter receives and parses the PS3 request (PS3 UI team)
- The adapter explodes that one request into many requests that call the Java API to (PS3 UI team)
- Each Java API calls back to a dependent service, concurrently when appropriate, to gather the content needed for that sub-request (API team)
- In the Java API, if a dependent service unavailable or returns a 4xx or 5xx, the Java API returns a fallback and/or an error code to the adapter (API team)
- Successful Java API transactions then return the content back to the adapter when each thread has completed (API team)
- The adapter can handle the responses from each thread progressively or all together, depending on how the UI team wants to handle it (PS3 UI team)
- The adapter then manipulates the content, retrieves the wanted (and prunes out the unwanted) elements, handle errors, etc. (PS3 UI team)
- The adapter formats the response in preparation for delivery back across the network to the PS3, which includes everything needed for the PS3 home screen in the single payload (PS3 UI team)
- The adapter finally handles the delivery of the payload across the network (PS3 UI team)
- The device will then parse this optimized response and populate the UI (PS3 UI team)
We are still in the early stages of this new system. Some of our devices have fully migrated over to it, others are split between it and the REST API, and others are just getting their feet wet. In upcoming posts, we will share more about the deeper technical aspects of the system, including the way we handle concurrency, how we manage the adapters, the interaction between the adapters and the Java API, our Groovy implementation, error handling, etc. We will also continue to share the evolution of this system as we learn more about it.
In the meantime, if you are interested in building high-scale, cloud-based solutions such as this one, we are hiring!
- Daniel Jacobson (@daniel_jacobson), Director of Engineering — Netflix API
No comments:
Post a Comment