April 15, 2021
RedisBloom
What is a Bloom filter?
A Bloom filter is a probabilistic data structure that provides an efficient way to verify that an entry is not in a set. This makes it especially useful when trying to search for items on expensive-to-access resources, such as over a network or on disk. With a large on-disk database, if you are trying to know if the key “foo” exists, it is possible to query the Bloom filter first. The Bloom filter query will return, with certainty, whether it potentially exists (and then the disk lookup can continue) or whether it does not exist, at which point you can forego the expensive disk lookup and simply send a negative reply up the stack.
While it’s possible to use other data structures to perform this, Bloom filters are also especially useful because they occupy very little space per element, typically counted in the number of bits (not bytes!). False negatives are not possible, but a percentage of false positives will exist, which is controllable, but for an initial test of whether a key exists in a set, they provide excellent speed, and most importantly, excellent space efficiency.
Bloom filters are used in a wide variety of applications:
- ad serving, making sure a user doesn’t see an ad too often;
- content recommendation systems, ensuring recommendations don’t appear too often,
- databases, quickly checking if an entry exists in a table before accessing it on disk.
How Bloom filters work
Most of the literature on Bloom filters use highly symbolic and/or mathematical descriptions to describe them. Here’s an alternate explanation:
A Bloom filter is an array of many bits. When an element is ‘added’ to a bloom filter, the element is hashed. Then bit[hashval % nbits] is set to 1. This looks fairly similar to how buckets in a hash table are mapped. To check if an item is present or not, the hash is computed and the filter checks to see if the corresponding bit is set or not.
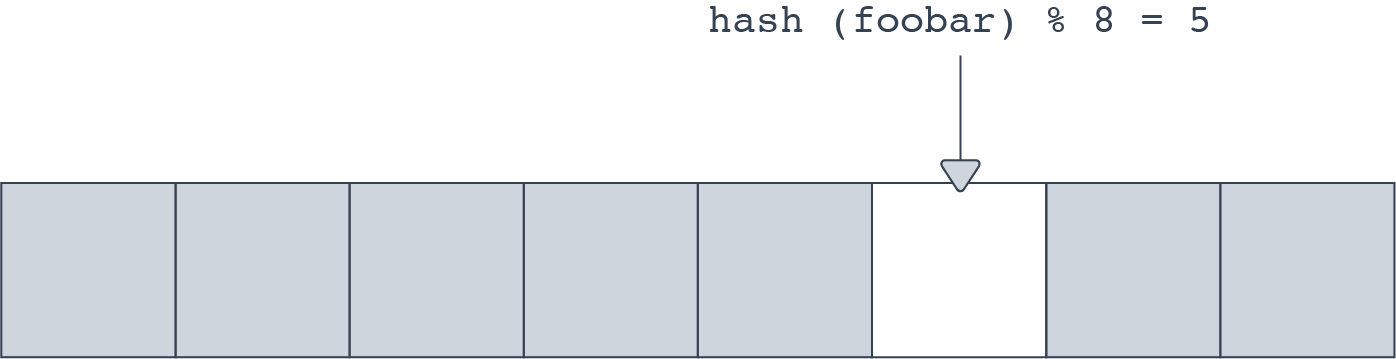
This is subject to collisions, of course. If a collision occurs, the filter returns a false positive, indicating that the entry is found. It is important to understand that a Bloom filter will never return a false negative, in other words, claim that something does not exist when it fact it is present.
In order to reduce the risk of collisions, an entry may use more than one bit: the entry is hashed bits_per_element (bpe) times with a different seed for each iteration, resulting in a different hash value. For each hash value, the corresponding hash % nbits bit is set. To check if an entry exists, the candidate key is also hashed bpe times, and if any corresponding bit is unset, then it can be determined with certainty that the item does not exist.
The value of bpe is determined at the time the filter is created. Generally the more bits per element, the lower the likelihood of false positives.

In the example above, all three bits would need to be set in order for the filter to return a positive result.
The accuracy of a Bloom filter affected by the fill ratio, or how many bits in the filter are actually set. When a filter has a vast majority of bits set, the likelihood of any specific lookup returning false is decreased, and likewise the possibility of the filter returning false positives is increased.
Scalable Bloom filters
Typically, Bloom filters must be created with foreknowledge of how many entries they will contain. The bpe number must be fixed, and likewise the width of the bit array is also fixed.
Unlike hash tables, Bloom filters cannot be “rebalanced” because there is no way to know which entries are part of the filter—the filter can determine if a given entry is not present but does not actually store the entries that are present.
In order to allow Bloom filters to scale and accommodate more elements than they’ve been designed to, they may be stacked. Once a single Bloom filter reaches capacity, a new one is created on top. Typically the new filter will have greater capacity than the previous one in order to reduce the likelihood of needing to stack yet another filter.
In a stackable (scalable) Bloom filter, checking for membership now involves inspecting each layer for presence. Adding new items now involves checking that the Bloom filter does not exist beforehand, and adding the value to the current filter. Hashes still need to be computed only once, however.
When creating a Bloom filter—even a scalable one—it’s important to have an approximation of how many items it is expected to contain. A filter with an initial layer that can contain only a small number of elements will significantly degrade performance because it will take more layers to reach a larger capacity.
RedisBloom in action
Here are a few examples of how RedisBloom works:
127.0.0.1:6379> BF.ADD bloom mark 1) (integer) 1 127.0.0.1:6379> BF.ADD bloom redis 1) (integer) 1 127.0.0.1:6379> BF.EXISTS bloom mark (integer) 1 127.0.0.1:6379> BF.EXISTS bloom redis (integer) 1 127.0.0.1:6379> BF.EXISTS bloom nonexist (integer) 0 127.0.0.1:6379> BF.EXISTS bloom que? (integer) 0 127.0.0.1:6379> BF.MADD bloom elem1 elem2 elem3 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:6379> BF.MEXISTS bloom elem1 elem2 elem3 1) (integer) 1 2) (integer) 1 3) (integer) 1
You can also create a custom Bloom filter. The BF.ADD command creates a new Bloom filter suitable for a smaller number of items. This consumes less memory but may be less ideal for large filters:
127.0.0.1:6379> BF.RESERVE largebloom 0.0001 1000000 OK 127.0.0.1:6379> BF.ADD largebloom mark 1) (integer) 1
Benchmarks, speed, and implementation
RedisBloom uses a modified version of libloom, with some enhancements:
- We discovered that when testing for presence, libbloom would continue checking for each bit even when an unset bit was discovered. Returning after the first unset bit increased performance.
- Decoupling the hash calculation API from the lookup APIs meant that RedisBloom only needed to compute the hash and feed it into the filter code.
- The table below shows a benchmark of setting a single Bloom filter with an initial capacity of 10,000, an error rate of 0.01, and a scaling factor of 2. Tests were conducted using a single-client thread, and with pipelining to avoid network/scheduling interference as much as possible:
| Implementation | Add | Check |
| Lua | 29k/s | 25k/s |
| bloomd | 250k/s | 200k/s |
| RedisBloom | 400k/s | 440k/s |
Creating a custom module
What’s in a module
Basically, modules contain command handlers—C functions with the following signature:
| int MyCommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) |
As can be seen from the signature, the function returns an integer, either OK or ERR. Usually, returning OK (even if returning an error to the user) is fine.
The command handler accepts a RedisModuleCtx* object. This object is opaque to the module developer, but internally it contains the calling client’s state, and even internal memory management, which we’ll get to later. Next it receives argv and argc, which are basically the arguments the user has passed to the command being called. The first argument is the name of the call itself, and the rest are simply parsed arguments from the Redis protocol. Notice that they are received as RedisModuleString objects, which again, are opaque. They can be converted to normal C strings with zero copy if manipulation is needed.
To activate the module’s commands, the standard entry point for a module is a function called int RedisModule_OnLoad(RedisModuleCtx *ctx). This function tells Redis which commands are in the module and maps them to their handler.
Writing a module
In this short tutorial we’ll focus on a simple example of a module that implements a new Redis command: HGETSET <key> <element> <new value>. HGETSET is a combination of HGET and HSET that lets you retrieve the current value in a HASH object and set a new value in its place, atomically. This is pretty basic, and could also be done with a simple transaction or a LUA script, but HGETSET has the advantage of being really simple.
- Let’s start with a bare command handler:
int HGetSetCommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
return REDISMODULE_OK;
}Again, this currently does nothing, it just returns the OK code. So let’s give it some substance.
- Validate the arguments
Remember, our command is HGETSET <key> <element> <new value>, meaning it will always have four arguments in argv. So let’s make sure this is indeed what happens:
/* HGETSET <key> <element> <new value> */
int HGetSetCommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
if (argc != 4) {
return RedisModule_WrongArity(ctx);
}
Return REDISMODULE_OK;
}RedisModule_WrongArity will return a standard error to the client in the form of:
(error) ERR wrong number of arguments for ‘get’ command.
- Activate AutoMemory
One of the great features of the Redis Modules API is automatic resource and memory management. While the module author can allocate and free memory independently, calling RedisModule_AutoMemory allows you to automate the creation of Redis resources and allocate Redis strings, keys and responses during the handler’s lifecycle.
RedisModule_AutoMemory(ctx);
- Perform a Redis call
Now we’ll run the first of two Redis calls, HGET. We pass argv[1] and argv[2], the key and element, as the arguments. We use the generic RedisModule_Call command, which simply allows the module developer to call any existing Redis commands, much like a Lua script:
RedisModuleCallReply *rep = RedisModule_Call(ctx, “HGET”, “ss”, argv[1], argv[2]);
// And let’s make sure it’s not an error
if (RedisModule_CallReplyType(rep) == REDISMODULE_REPLY_ERROR) {
return RedisModule_ReplyWithCallReply(ctx, srep);
}Notice that RedisModule_Call’s third argument, “ss,” denotes how Redis should treat the passed variadic arguments to the function. “ss” means “two RedisModuleString objects.” Other specifiers are “c” for a c-string, “d” for double, “l” for long, and “b” for a c-buffer (a string followed by its length).
Now let’s perform the second Redis call, HSET:
RedisModuleCallReply *srep = RedisModule_Call(ctx, “HSET”, “sss”, argv[1], argv[2], argv[3]);
if (RedisModule_CallReplyType(srep) == REDISMODULE_REPLY_ERROR) {
return RedisModule_ReplyWithCallReply(ctx, srep);
}Using HSET is similar to the HGET command, except that we pass three arguments to it.
- Return the results
In this simple case, we just need to return the result of HGET, or the value before we changed it. This is done using a simple function, RedisModule_ReplyWithCallReply, which forwards the reply object to the client:
RedisModule_ReplyWithCallReply(ctx, rep); return REDISMODULE_OK; }
And that’s it! Our command handler is ready; we just need to register our module and command handler properly.
- Initialize the module
The entry point for all Redis Modules is a function called RedisModule_OnLoad, which the developer has to implement. It registers and initializes the module, and registers its commands with Redis so that they can be called. Initializing our module works like this:
int RedisModule_OnLoad(RedisModuleCtx *ctx) {
// Register the module itself – it’s called ‘example’ and has an API
version of 1
if (RedisModule_Init(ctx, “example”, 1, REDISMODULE_APIVER_1) == REDISMODULE_ERR) {
return REDISMODULE_ERR;
}
// register our command – it is a write command, with one key at argv[1]
if (RedisModule_CreateCommand(ctx, “HGETSET”, HGetSetCommand, “write”, 1, 1, 1) == REDISMODULE_ERR) {
return REDISMODULE_ERR;
}
return REDISMODULE_OK;
}And that’s about it! Our module is done.
- A word on module building
All that’s left is to compile our module. Without going into the specifics of creating a makefile for it, what you need to know is that Redis Modules require no special linking. Once you’ve included the redismodule.h file in your module’s files and implemented the entry point function, that’s all Redis needs to load your module. Any other linking is up to you. The commands needed to compile this basic module with gcc are:
On Linux: $ gcc -fPIC -std=gnu99 -c -o module.o module.c $ ld -o module.so module.o -shared -Bsymbolic -lc On OSX: $ gcc -dynamic -fno-common -std=gnu99 -c -o module.o module.c $ ld -o module.so module.o -bundle -undefined dynamic_lookup -lc
- Loading the module
Once you’ve built your module, you need to load it. Assuming you’ve downloaded Redis from its latest stable build (which supports modules), you just run it with the loadmodule command-line argument:
redis-server –loadmodule /path/to/module.so
Redis is now running and has loaded our module. We can simply connect with redis-cli and run our commands!
Getting the source
The full source code detailed here can be found as part of RedisModuleSDK, which includes a module project template, makefile, and a utility library (with functions automating some of the more boring stuff around writing modules that are not included in the original API). You do not have to use it, but feel free to do so.
No comments:
Post a Comment