说明
Dynamo是Amazon设计的分布式KV存储系统。是为了满足Amazon庞大的电商业务而孕育的产物。Amazon的业务场景对存储系统提出以下严苛的要求:
- 系统高度可扩展:可以通过增加节点实现容量和性能的线性扩展
- 系统高可靠:决不能丢数据
- 系统高可用:在Amazon的业务场景中,要做到”Always-Write”
除此之外,Amazon的许多业务的数据模型相对比较简单,只需要通过Primary key去找到其数据内容,而且多数情况下数据内容比较小。这也意味着无需使用传统的关系型数据库的复杂数据模型。
Dynamo就是针对Amazon的这些应用场景而设计出来的底层存储系统,具备如下特点:
- 简单的存取模式,只支持KV模式的数据存取,对象小于1M
- 高可用性,即便在集群中部分机器故障,网络中断,甚至是整个机房下线,仍能保证用户对数据的读写
- 高可扩展性,除了能够跨机房部署外,动态增加,删除集群节点,同时对正常集群影响很小
- 数据的高可用性大于数据的一致性,短时间的数据不一致是可以容忍的,采用最终一致性协议
- 服务SLA保证条约,99.9%的请求要在300ms内返回
系统架构
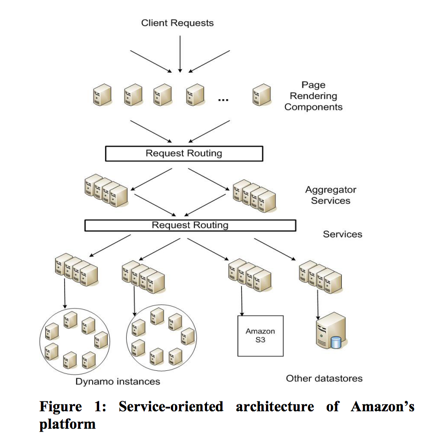
上图描述了Amazon内部服务化的系统设计。请求从客户端发起,经过中间层的路由,最终到达底层的存储系统,如Dynamo,Amazon S3。我们在这里只讨论Dynamo的设计。
核心技术
一个分布式存储系统需要解决如下几个关键问题:
- 数据如何分布
- 数据可靠性
- 数据一致性
数据布局
关于数据如何布局,主要有两种思路:查表式和计算式。所谓查表式,即通过维护全局统一的映射表,需要访问数据时,先查询该表定位数据所在节点。计算式无需维护该映射表,需要访问数据时,通过一定规则计算出数据所在位置。
查表式和计算式各有优劣:
- 查表式需要一个中心服务器维护全局的映射表信息,这可能成为系统的瓶颈;
- 而计算式的主要问题在于存储节点的变更可能带来大量的数据迁移,增加系统复杂度。
查表式的代表是GFS,Dynamo则采用的是计算式。计算式的简单抽象如下图:
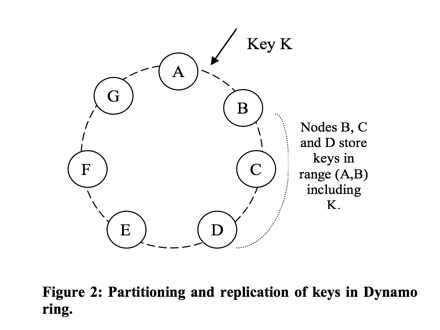
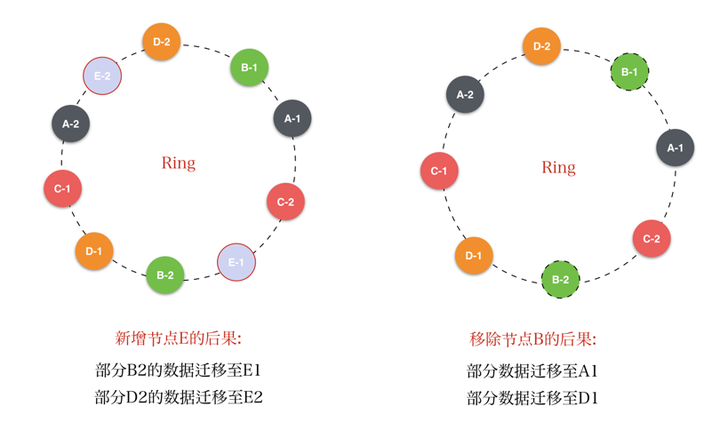
整个系统在一个特定的环形运算空间,我们称为Ring。运算空间的大小可自己定义,例如,该空间范围取值为[0, 2**32 - 1],而之所以称为环形空间是当超出该值后继续归零。
对存储系统中的每个节点的特征值在该空间内进行运算,例如,取节点的特征为其IP地址,对其ip地址进行hash运算,然后在运算空间内取模,得到其在环形运算空间上的值。如上图,A~G每个节点根据其运算得到的值而位于该Ring上的不同位置。
写入对象数据时,首先根据对象key(一般是对象名)在运算空间内计算其特征值,然后在该Ring上沿着顺时针方向查找与其特征值最接近的节点。例如上图的对象K,计算其特征值位于A、B节点之间,根据规则,那K应该被存储在节点B上。
这种方法看似完美,一次计算即可得出其存储节点最终位置。但可能带来以下的致命问题:
- 新增一个节点,原本存储在Ring上与其相邻节点的数据现在落在了该新增节点上,那势必需要进行数据迁移;
- 移除一个节点,那原本由该节点负责的数据接下来要由其相邻节点负责,也会带来数据的迁移。
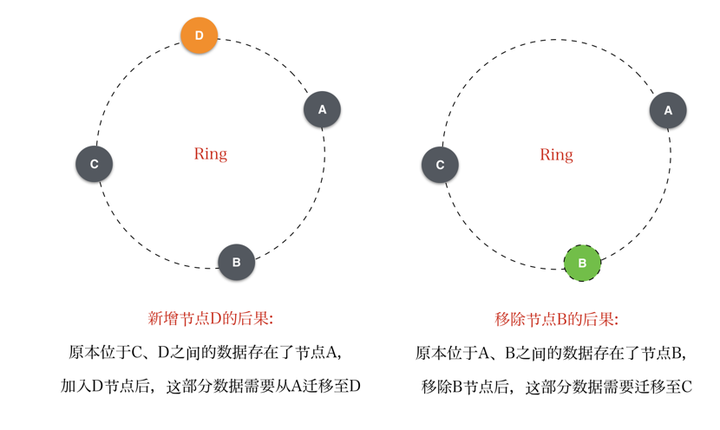
由于计算式数据定位的天然特性,数据迁移的问题根本无法避免。但是上面的方案的问题是数据迁移发生在两个相邻节点之间,如果每个节点存储的数据量很大,那数据迁移带来的压力势必会影响参与迁移的节点正常的请求,导致不可用。
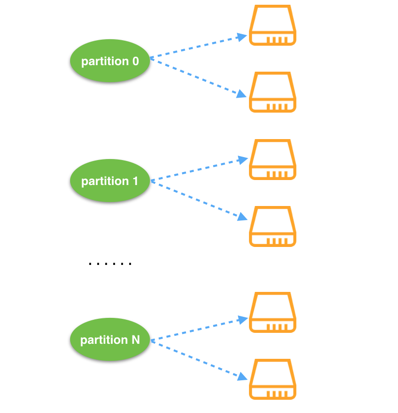
既然无法避免,那就尽量缓解。Dynamo设计中引入了虚拟节点(partition)。所谓的虚拟节点其实就是在一个物理节点(如上面的A/B/C/D)上虚拟出多个逻辑节点。例如A-1、A-2、A-3 ……,将这些虚拟节点参与环形运算空间的计算,如下图:
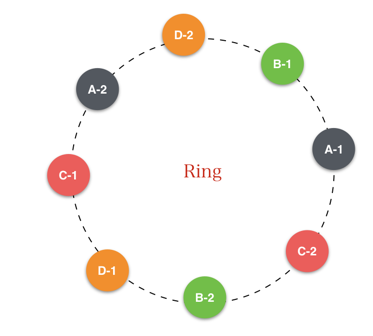
上图中每个物理节点虚拟出了两个逻辑节点,定位时,首先根据对象key计算其所在的虚拟节点,最后查表知道该虚拟节点位于的物理节点。相当于是一个二级映射函数。
这样做法的好处时,在新增或者移除节点时,会有更多的节点参与到数据迁移过程中,提升迁移效率,但是却无法从根本上避免数据迁移。
从理论分析就知道数据迁移过程参与的节点更多了,效率自然就提升了。
而物理节点如何划分虚拟节点,个人感觉根据实际的使用场景来决定。例如,jedis就使用虚拟ip(真实ip后加上节点编号)。
在存储系统中,物理节点其实抽象的是磁盘,虚拟节点其实就是代表了磁盘上的某个目录(经常称之为Partition)。而一般虚拟节点的数目固定,为2**N个。这样,对象key与虚拟节点的映射关系就可以保持固定,改变的是虚拟节点至物理节点的映射关系。
这种二级映射带来的好处是:
- 一级映射时增加节点移动的数据单位是单个对象,扫描计算哪些对象需要移动时代价太大;
- 二级映射时节点变化只影响虚拟节点的情况,新增或者移除节点(磁盘设备)时只需要迁移虚拟节点的数据即可,管理的成本大大减少。
引入虚拟节点后,典型的数据定位流程是:
- 根据对象名计算MD5,并取MD5的低N位得到虚拟节点编号(这也是为什么虚拟节点数目最好选择2的N次方的原因);
- 查表获得虚拟节点所在的物理节点
数据可靠性
保证数据高可靠性的做法一般是使用多副本:即一个对象的数据被写入多个虚拟节点,而且还得要求这多个虚拟节点位于不同的物理节点上。对于存储系统来说,要求多副本位于不同的机器的不同磁盘上。
一般来说,系统在初始化时便会根据系统当前的物理节点数量为每个虚拟节点分配多个物理节点作为多副本:
每个虚拟节点使用如下规则选择其多个存储副本:
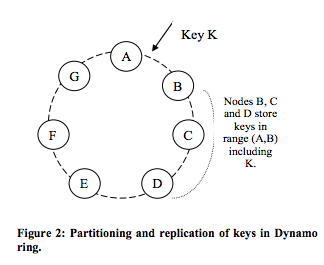
对象K根据计算应该落在虚拟节点B上,同时,会选择B的后继虚拟节点C、D作为另外两个副本。但是需要注意的是B、C、D三个虚拟节点必须位于不同的物理节点。
数据一致性
既然存在数据多副本,那就不得不探究下多副本之间的数据一致性问题。Dynamo采用的是最终一致性模型:即虚拟节点的多个副本之间可能会存在不一致的时间窗口,但最终系统会保证多个副本之间数据达成一致。
之所以存在数据不一致窗口,是因为Dynamo为了降低写延迟,客户端将数据推送至虚拟节点的主副本后,该副本除写本地外,还将数据推送至其他副本,但是该副本可以选择等到或者不等其他副本返回应答即可给客户端响应说数据已经正确写入。这时候如果客户端去读那些还没来得及写入数据的副本,便会读不到数据或者读到旧数据,出现数据不一致。
Dynamo使用W+R>N的策略来保证读取数据的正确性:
W:数据写入时返回给客户端前保证已经写入的副本数
R:数据时需要读取的副本数
N:对象副本数
根据鸽笼原理,只W+R>N,便可以保证客户端一定能读到最新版本的数据。
那这就带来了另外一个问题:如何在多个数据副本之间判断谁的数据更新?
Dynamo使用向量时钟来解决该问题。简单来说,接受客户端写请求的副本会为该数据的本次更新增加一个逻辑时间戳,该时间戳为一个二元组<updater, version>
updater:更新的执行者
version:本次更新的版本号
例如,A本地对象object的当前版本为<A, 1>,接下来A又收到客户端的对象更新请求,那么A更新对象数据的同时,将其版本修改为<A, 2>。
假如该对象有另外一个副本位于节点B,B上该对象的版本依然为<A, 1>,如果客户端的更新请求没有发往A,而是发到了B(这是有可能的,因为很可能客户端和A之间发生了网络分区)。B更新对象数据的同时,更新其版本为<A, 1>, <B, 1>,然后将本次更新连同其版本一并发送至其他副本节点。
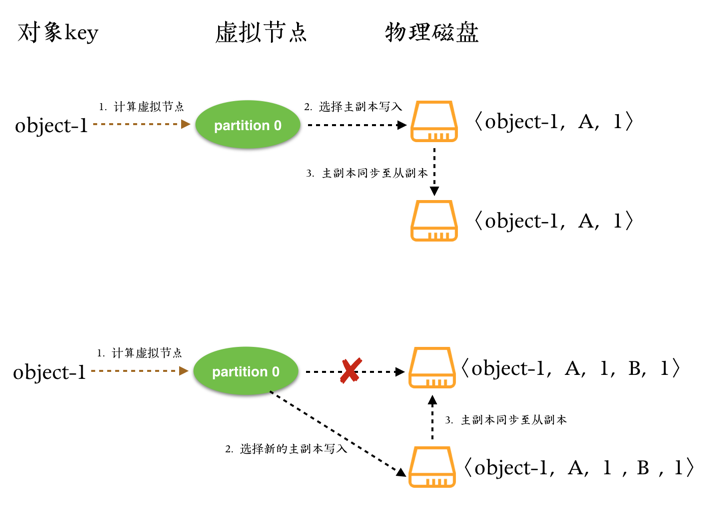
上图演示了对于一个对象的两次更新过程,第二次中原来的主副本和客户端之间出现了网络不连通的问题,导致客户端选择出了新的主副本。

上图演示了在主从同步出现延迟的情况下客户端的连续数据更新导致数据版本的冲突问题。
客户端读数据时,会根据R的设置从多个副本中读出数据,然后对比副本数据的向量时钟的版本,选择最新的数据版本返回给客户端。但是有可能出现无法合并的情况,例如上面的A节点上数据版本为<A, 2>,B节点上数据版本为<A, 1>, <B, 1>。遇到这种情况,只能交给应用去选择合并了。
再考虑下面这种并发更新的情况:
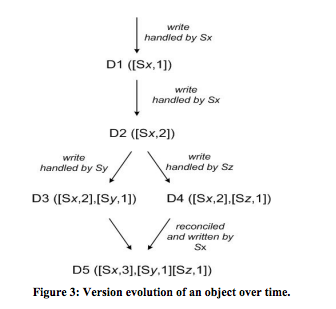
系统当前是三副本,某个partition的三个副本分别为Sx,Sy,Sz,且R=2, W=2。按照下面的顺序进行数据更新:
- 数据在Sx节点写入,产生数据的新版本为<Sx, 1>,并同步至Sy,Sz;
- 数据在Sx节点更新,产生数据新版本为<Sx,2>,并同步至Sy,Sz;
- 截止目前,Sx,Sy,Sz三个节点的数据版本均为<Sx, 2>,数据处于一致状态;
- 由于某种原因,A客户端选择了Sy节点对数据进行更新,而此时A客户端看到的数据版本为<Sx, 2>,因此,A向Sy节点发送数据更新请求,且指明本次更新的版本为<Sx, 2>,Sy节点收到更新请求后,选择更新本地数据的版本为<Sx, 2>,<Sy, 1>;
- 在4进行的过程中,客户端B选择了Sz节点对数据进行更新,此时B客户端看到的数据版本也是<Sx, 2>,于是B给Sz发送请求更新对象的<Sx, 2>的版本数据。Sz同样更新本地的数据以及版本为<Sx, 2>, <Sz, 1>;
- 接下来数据主从同步的过程中,无论是Sy将自己的数据同步至Sz,还是Sz将数据同步至Sy,都会发现他们之间的数据其实是存在冲突的,而且存储系统自身是无法解决这种冲突的,于是,继续保存这种冲突数据,但是在Sy(或者Sz)向Sx同步数据的时候是没问题的,因为通过向量时钟比对发现Sx的版本无论比Sy还是Sz都要更小;
- 接下来,客户端发起对数据的读请求,因为存在冲突,冲突的版本都会被发送至客户端,于是客户端看到的数据版本是{<Sx, 2>, <Sy, 1>}和{<Sx, 2>, <Sz, 1>}。接下来应用程序根据自己的业务逻辑尝试去解决冲突,例如,最终选择了{<Sx, 2>, <Sy, 1>}作为最终的数据,那接下来会将自己的协调结果写到某个副本(假如选择Sx写入)上,需要注意的是,客户端指定更新的版本为<Sx, 2>, <Sy, 1>, <Sz, 1>,而Sx收到请求后,会将对象的版本更新为<Sx, 3>,<Sy, 1>, <Sz, 1>。如此这样,接下来Sx将新版本的数据推送到其他副本的时候,就不会在出现冲突了,因为无论是Sy节点上的<Sx, 2>, <Sy, 1>还是Sz节点上的<Sx, 2>, <Sz, 1>均落后于Sx上的当前版本,大家又达成了数据一致性
Handoff机制
所谓的HandOff机制是对Dynamo可用性的进一步提升手段。如同我们上面说到,正常情况下,客户的写入数据会被复制到ring上的N个节点。但是一旦出现异常时,写入的节点不可达,这时候可能就会出错,如下:
假如数据应该被写入至节点A并复制到B和C,但是此时假如A节点异常,可能就会导致数据不可写。
Dynamo的做法是引入Handoff节点,例如这里的D作为A的Handoff,A节点不可写的时候,数据会被写入D,但是在D上这些数据会被存储在特殊位置并且有元数据信息描述该数据的原始位置(A)。一旦D检测到A节点恢复,就会将该本来不属于自己的数据迁移至原本的位置(A)。
节点状态探测
使用Gossip协议来在所有节点之间维护集群的map信息。具体的可以参考论文,但这种做法看起来是复杂了点。
关键流程
在Dynamo的对象副本中,存在一个副本充当协调者的角色,称之为coordinator。该协调者负责处理客户端的读写请求。
写流程
coordinator接受客户的写请求,处理:
- 为该请求生成向量时钟或者更新对象已有的向量时钟并将数据及其时钟更新至本地
- 将更新请求发送至所有其他副本;
- 只要收到其他W-1个副本的回应,就认为本次写成功,给客户端返回响应。
读流程
coordinator接受客户的读请求,处理:
- coordinator将请求发送至所有其他副本;
- 只要收到其他R-1个副本的回应,coordinator认为本次读成功;
- coordinator对R个副本(包括自己的一个副本)的内容进行merge,取最新的版本返回给客户端;如果发生冲突无法决定谁的版本最新,那么coordinator就会将产生冲突的版本全部发给客户端;
- 客户端如果收到了多个冲突版本,会自己解决冲突并将解决的结果写入coordinator,通知其以该版本为最新,后续所有的读取就不再会产生冲突了。
实现细节
在Dynamo中,存储节点主要由三个主要部分组成:
请求处理器
成员管理和错误检测
存储引擎
模块化存储引擎设计
Dynamo底层的存储引擎使用模块化设计,支持可插拔,支持诸如BDB、Mysql等作为底层数据存储容器。
负载均衡
我们前面说过无论读写都存在一个coordinator角色,客户端的所有访问都经过该coordinator,这导致的一个问题是该coordinator的复杂会超过其他副本。好处是所有的读写都串行化了,可以保证数据的一致性。但是缺点也是显而易见的:如果所有的写都是随机选择coordinator,那么很难保证数据副本之间的一致性。假如客户端A写入副本1,而客户度B选择向副本2写入,如果此时A和B并发写的话,那毫无疑问最终会错乱,在一个时间窗口内,会出现数据的不一致。不过想了想,好像Dynamo的应用场景主要是一次写多次读的场景,这种情况并不常见,这个问题待讨论。
No comments:
Post a Comment