April 18, 2021
Here is the link. I am not sure the quality of article. I just quickly googled and chose one to read.
- ElasticSearch is a highly scalable open-source full-text search and analytic engine.
- A distributed system on top of Lucene Standard Analyzer for indexing and automatic type guessing and utilizes a JSON based REST API to refer to Lucene features.
- Lucene Standard Analyzer
- indexing and automatic type guessing
- a JSON based REST API to refer to Lucene featureas
- Elasticsearch is standing as a NOSQL DB
An Overview on Elasticsearch and its usage
A brief introduction
Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. It is generally used as the underlying engine/technology that powers applications that have complex search features and requirements. Elasticsearch provides a distributed system on top of Lucene Standard Analyzer for indexing and automatic type guessing and utilizes a JSON based REST API to refer to Lucene features.
It is easy to set up out of the box since it ships with sensible defaults and hides complexity from beginners. It has a short learning curve to grasp the basics so anyone with a bit of efforts can become productive very quickly. It is schema-less, using some defaults to index the data.
In the case of consumers searching for product information from Ecommerce websites catalogs are facing issues such as a long time in product information retrieval. This leads to poor user experience and in turn missing the potential customer. Today business is looking for alternate ways where the big amount of data is stored in such a way that the retrieval is quick.
This can be achieved by adopting NOSQL rather than RDBMS (Relational Database Management System) for storing data.
Elasticsearch is standing as a NOSQL DB because:
- it easy-to-use
- Has a great community
- Compatibility with JSON
- Broad use cases
Backend components
To better understand Elasticsearch and its usage is good to have a general understanding of the main backend components.
Node
A node is a single server that is part of a cluster, stores our data, and participates in the cluster’s indexing and search capabilities. Just like a cluster, a node is identified by a name which by default is a random Universally Unique Identifier (UUID) that is assigned to the node at startup. We can edit the default node names in case we want to.
Cluster
A cluster is a collection of one or more nodes that together holds your entire data and provides federated indexing and search capabilities. There can be N nodes with the same cluster name.
Elasticsearch operates in a distributed environment: with cross-cluster replication, a secondary cluster can spring into action as a hot backup.
Index
The index is a collection of documents that have similar characteristics. For example, we can have an index for a specific customer, another for a product information, and another for a different typology of data. An index is identified by a unique name that refers to the index when performing indexing search, update, and delete operations. In a single cluster, we can define as many indexes as we want. Index is similar to database in an RDBMS.
Document
A document is a basic unit of information that can be indexed. For example, you can have an index about your product and then a document for a single customer. This document is expressed in JSON (JavaScript Object Notation) which is a ubiquitous internet data interchange format. Analogy to a single raw in a DB.
Within an index, you can store as many documents as you want, so that in the same index you can have a document for a single product, and yet another for a single order.
Shard and Replicas
Elasticsearch provides the ability to subdivide your index into multiple pieces called shards. When you create an index, you can simply define the number of shards that you want. Each shard is in itself a fully-functional and independent “index” that can be hosted on any node in the cluster.
Shards is important cause it allows to horizontally split your data volume, potentially also in multiple nodes parallelizing operations thus increasing performance. Shards can also be used by making multiple copies of your index into replicas shards, which in cloud environments could be useful to provide high availability.
The Elastic stack
Although search engine at its core, users started using Elasticsearch for logs and wanted to easily ingest and visualize them. Elasticsearch, Logstash, Kibana are the main components of the elastic stack and are know as ELK.
Kibana
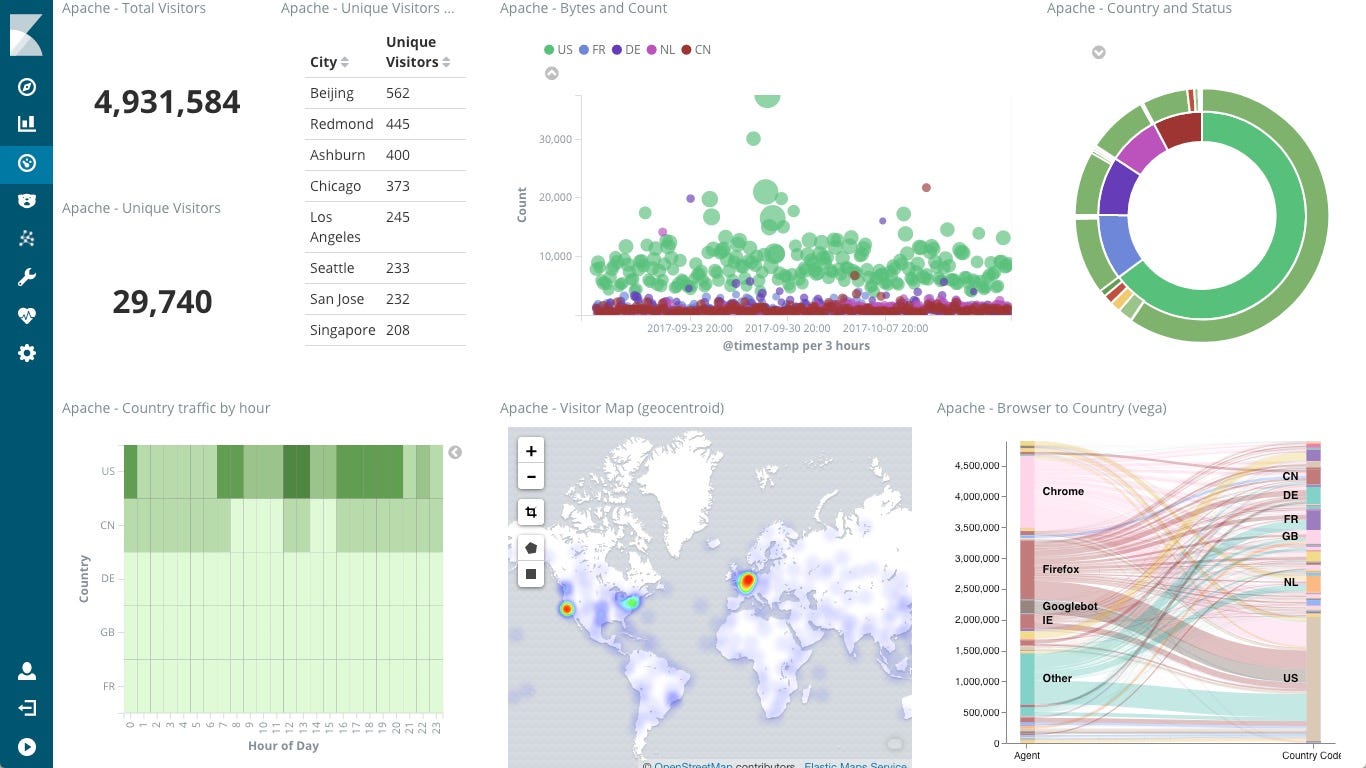
Kibana lets you visualize your Elasticsearch data and navigate the Elastic Stack. You can select the way to give shape to your data by starting with one question to find out where the interactive visualization will lead you. You can begin with the classic charts (histograms, line graphs, pie charts, sunbursts, and so on) or design your own visualization and add Geo data on any map.
You can also perform advanced time series analysis, find visual relationship in your data and explore anomalies with machine learning features.
For more details have a look at the official page.

Logstash
Logstash is an open source, server-side data processing pipeline that ingests data from a multitude of sources simultaneously, transforms it, and then sends it to collect.
Data is often scattered or soiled across many systems in many formats. On Logstash is possible to ingest logs, metrics, web applications, data stores, and various AWS services, all in continuous streaming fashion. It can be used with different modules like Netflow, to gain insights to your network traffic.
It dynamically transforms and prepares data regardless of format by identifying named fields to build structure, and transform them to converge on a common format. You can use the monitoring feature in X-Pack to gain deep visibility into metrics about your Logstash deployment. In the overview dashboard, you can see all events received and sent by Logstash, plus info about memory usage and uptime. Then you can drill down to see stats about a specific node. More details at the official page.


Elasticsearch use cases
Elasticsearch can be used in so various ways that is difficult for me to capture all the most interesting use cases. For simplicity, I have selected three main categories and three main companies use cases, if you want to dive more you can have a look at their use cases page .
- Main data store: Create searchable catalog, document store and logging system.
- Complementary Technology: add visualization capabilities to SQL, mongoDB, cast indexing and search to Hadoop, or add processing and storage to kafka.
- Additive technology: In case you have already logs in Elasticsearch, you may want to add metrics, monitoring, and analytics capabilities.
Netflix
Netflix messaging system behind the scene is using Elasticsearch. The messaging system is divided in the following categories:
- The message you receive when you join the service.
- Once people joined they receive messages about the content they might enjoy or new feature on the server.
- Once they know more about you through Machine Learning algorithms, they send more engaging and personalized messages about what you might like or enjoy to watch.
- In case you decide to leave the service they tell you how to come back.
This is all done through emails, app push notifications, and text messages. To accomplish that in an efficient way they need to know almost instantly about possible issues in the delivery of the message. For this reason Elasticsearch was introduced (previously they were using distributed grep) for message life cycle.
In a nutshell each status message is recorded on Elasticsearch and the proper team is able to filter each category by writing a query on Kibana.
Let’s say a new movie has been introduced, in this case the “new title” message must be delivered to all customers.
Using Kibana they can see in real time how many people got notified with the new message and the message delivery success rate. They can also verify the reason why some of the messages have failed. This has introduced the ability to investigate and tackle issues much faster such as the high rate message failure in Brazil in 2012.
By using a pie chart in Kibana they were able to find out almost instantly a huge amount of invalid memberships failures. Following up with the National provider they discovered that on July 29 the digit 9 was added to the left of all existing mobile numbers in many Brazilian regions, regardless of their former initial digits. This change was meant to increase the numbering capacity in metropolitan areas like São Paulo, thereby eliminating the perennial shortage of available numbers in that area.
Thanks to Elasticsearch they had the capability to discover all these failures near real-time and promptly follow up with the provider.
Tinder
This is an example of a mutual collaboration between a big tech company and the Elasticsearch community.
Tinder at its core is a search engine. The search queries are complex with double digits events, hundreds countries, and more than 50 languages.
Most users interactions trigger an Elasticsearch query.
There are different ways to interact with tinder based on locations. For example in Asia they also use it as a language exchange or to search for a tour guide.
for this reason the queries in Tinder are very complex. They must be:
- Personalized: Machine Learning algorithms are also utilized in this context.
- Location based: to find a match based on where you are at a certain point in time.
- Bidirectional: to know which users will swipe right on each other, which basically means a match.
- Realtime: The entire interaction has to happen within milliseconds from a massive amount of users and with many variables associated with each of them.
Considering all these functionalities the backend reality is very complex broadening from data science and machine learning, to bidirectional ranking and geolocation. Elasticsearch cornerstone is to make those components work together in a very efficient way.
In this situation performance is a hurdle. For this reason they have been cooperating with the Elasticsearch team to fine-tune many parameters and to solve bugs. In this way they have been supporting the Elasticsearch community and helped to improve the overall Elastic stack product while improving the user experience of Tinder itself.
Cisco Commerce Delivery Platform
Elasticsearch was introduced in 2017 when they upgraded their commercial platform. They switched from RDBMS to Elasticsearch for the following reasons:
- Add Fault Tolerance working in active/active mode. RDBMS are not distributed and are not fault tolerant.
- Rank based and type ahead Search for data sourced from multiple Databases on 30/40 attributes to get sub-seconds responses.
- Global search: if no specific objects are specified in your search, the search engine will find results against multiple objects.
Cisco Threat intelligence department
In a nutshell Cisco Threat Intelligence department or Cisco Talos is what is keeping malware and spams from over saturating the “internet pipes”.
In this Cisco department they view more than 1.5 Millions malware samples on a daily basis. Malicious payloads and spams make up 86% of all email traffic (more than 600 billions emails daily).
Threat intelligence team in Talos are the guys who find out new global scale vulnerabilities on the web and locate the real bad guys.
They detect new exploit kits by analyzing traffic patterns with ssh terminals and router honeypots to collect anomalous behaviors like attempted logins using brute-force attacks to guess users and passwords. In this way they record what commands attackers are using once they login, what file they download and upload from and to the server (although difficult to believe, most credentials on the internet are as simple as row password and username admin).
They are the ones who stopped the so called SSHPsychos in 2015. This group was well known for creating significant amounts of scanning traffic across the Internet by generating SSH brute force login attempts from a specific class of IPs. Once they were able to enter a server as root, they were downloading and installing DDoS rootkits.
Since 2017 they use logstash and kibana to detect and analyze possible global scale threads.
Conclusions
Elasticsearch is a distributed, RESTful and analytics search engine capable of solving a wide variety of problems.
Many companies are switching to it and integrating it in their current backend infrastructure since:
- It allows to zoom out to your data using aggregation and make sense of billions of log lines.
- It combines different type of searches: structured, unstructured, Geo, application search, security analytics, metrics, and logging.
- It is really fast and it can run the same way on you laptop with a single node or on a cluster with hundreds of servers, making very easy prototyping.
- It uses standard RESTful APIs and JSON. The community has also built and maintains clients in many languages such as Java, Python, .NET, SQL, Perl, PHP etc.
- It is possible to put the real-time search and analytics features of Elasticsearch to work on your big data by using the Elasticsearch-Hadoop (ES-Hadoop) connector.
- Tools like Kibana and Logstash allow you to make sense of your data in very simple and immediate ways by using charts and performing granular searches.
In this article we have only scratched the surface of Elasticsearch power and use cases, and the variety of business challenges is able solve. If you are interested to know more or to test it, have a look at their product page and their tutorials for a quick start. If you are curios on how to create a basic search-only app using django and elasticsearch, I encourage you to check out my previous articles.
No comments:
Post a Comment