January 4, 2021
Introduction
I like to work on bigtable study by watching the video every day about Google cloud, bigtable. After a few months, I started to google more about some concepts. One is about bigtable field promotion.
Cloud Bigtable & time series data | Medium article
I like to copy the content in the following:
Here is the article.
Cloud Bigtable & time series data
DA @ Google; http://goo.gl/bbPefY | http://goo.gl/xZ4fE7 | https://goo.gl/RGsQlF | http://goo.gl/4ZJkY1 | http://goo.gl/qR5WI1
8.9K Followers
Despite its importance in multiple industries, time series data continues to be one of the more challenging datasets to handle at scale. Time series help us identify trends in data, letting us demonstrate concretely what happened in the past and make informed estimates about what will happen in the future.
But for TIMESLIDERS, time series data was the backbone of their business, but also the bane of their users. TIMESLIDERS is a mobile-application performance library, built for developers. Their client application would monitor as many performance details about the client device and application as possible, reporting things back like avg network speed, quality of wifi connection, battery life, foreground activity paint rate, etc, etc.
Clients could then log into a portal and see a plethora of performance statics on how their app was performing around the world, on real devices.
Sadly, this process of building and displaying these performance tables quickly became a bottleneck, and a less-than-ideal experience for the majority of their clients.
Thankfully, we didn’t have to look far to find the problem : In order to build their graphs, the very first thing they did was query by timestamp.
Many schema designers are inclined to define a root table that is timestamp ordered, and updated on every write. Unfortunately, this is one of the least scalable things that you can do with Cloud Bigtable.
What’s going wrong?
Let’s be clear: Storing time-series data in Cloud Bigtable is a natural fit. Cloud Bigtable stores data as unstructured columns in rows; each row has a row key, and row keys are sorted lexicographically.
There are two commonly used ways to retrieve data from Cloud Bigtable:
- You can get a single row by specifying the row key.
- You can get multiple rows by specifying a range of row keys.
These methods are ideal for querying time-series data, since you often want data for a given time range (for example, all of the market data for the day, or server CPU statistics for the last 15 minutes). As a result, Cloud Bigtable is functionally a great fit for time series.
Of course, there’s always a devil in the details, and for time series data, this is no exception. In brief, when a row key for a time series includes a timestamp, all of your writes will target a single node; fill that node; and then move onto the next node in the cluster, resulting in hotspotting.
Properly handling time series data
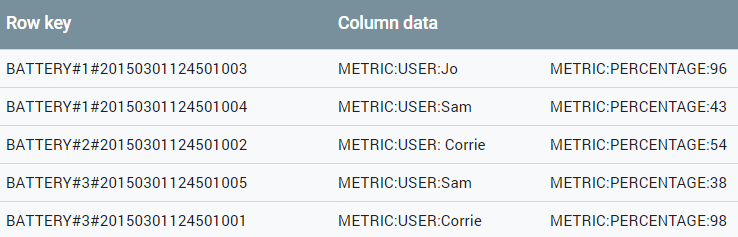
Let’s take a simple example from TIMESLIDERS: Storing battery status. Every 100ms or so, their app would log the battery status, creating an entry into Bigtable where the row key consists of the word “BATTERY” plus a timestamp. (for example: BATTERY20150501124501003).
The problem with this, is that the row key will always increase in sequence, meaning every row will have a high level of adjacency to every other row; And because Cloud Bigtable stores adjacent row keys on the same server node, all writes will focus only on one node until that node is full, at which point writes will move to the next node in the cluster. During this time, you end up with a large level of hotspotting.
So we need the ability to query a set of timestamped rows for our graph, but need to find a way to do it that doesn’t result in hotspotting.
Thankfully, there are a few ways to solve this problem.
Field promotion involves moving fields from the column data into the row key to make writes non-contiguous. For example, TIMESLIDERS could promote the USERID from a column to an element of the row key. This change would solve the hotspotting issue because user identifiers will provide a more uniform distribution of row keys. As a result, writes will be split across multiple nodes in their cluster.
The advantage of field promotion is that it often makes your queries more efficient as well, making this strategy a clear winner. The (slight) disadvantage is that your queries are constrained by your promoted fields, leading to rework if you don’t promote the right fields.


Another option is Salting, which adds an additional calculated element to the row key to artificially make writes non-contiguous. For example, take a hash of the timestamp and divide it by the number of nodes in the cluster (to help balance traffic) and append the remainder to the row key.
The advantage of salting is its simplicity — it’s essentially a simple hashing function that helps balance access across nodes.
On the other hand, it does require an extra step when you query for time ranges. You’ll have to do one scan per salt-value, and then recombine the results in your own code. Salting also makes it much harder to troubleshoot performance issues with Key Visualizer for Cloud Bigtable, because it’ll show row keys with a bunch of hashed values instead of human-readable strings.

The fix is in!
For TIMESLIDERS salting was problematic. Despite a barrage of tests, it was very difficult to choose a salt value that both distributes activity across nodes and still remained valid as their system scaled up and down.
As such, they decided to use field promotion, which allowed them to avoid hotspotting in almost all cases, and tended to make it easier to design a row key that facilitates queries.
Oh Hey!
It’s worth pointing out that time series data is a common enough challenge with Bigtable, that there exists a 3rd party library that can do all the heavy lifting for you. If you’re not interested in solving all these problems yourself, check out OpenTSDB which can save you a ton of headache later on.
Follow up
Jan. 28, 2022
I like to read one more time and learn better about field promotion. Hotkey issue is also my favorite learning here as well.
No comments:
Post a Comment