Sept. 16, 2021
Here is the article.
I like to learn how to write an article on medium. The following should be definitely great learning example.
As we transition to cloud we need to adapt our way of thinking about availability and reliability in order to get the most out of the cloud platform and achieve the kind of continuous availability that internet services such as Google’s search, gmail, and many others practically achieve.
Introduction
This post is the third in a series that covers the following topics:
- Background and the goal
- Key concepts (design patterns, SRE, etc )
- GCP Services for high availability (this post)
My intention in this post is to highlight some of GCP’s products from the availability perspective and give you some idea of the design and configuration choices you face in the context of the Key Concepts of the previous post. All of these services have high availability SLAs or SLOs associated with them. The products, their SLAs and their documentation evolve constantly so I will specifically try to minimize any replication of the official documention.
Google’s Infrastructure
Google and Google Cloud operate an ever increasing number of data centers around the world as Regions and Zones all connected by a global, privately operated fibreoptic backbone.
A Region is geographically separated from other regions and always has multiple fiber-optic backbone cable connections that provide redundancy and low latency communications with other regions. For example Tokyo and Osaka are Regions in Japan and each has multiple redundant cables providing direct connects to locations in Northern America and the Asia Pacific including Australia. This redundancy means that network partitions are extremely rare on Google’s network.
Regions are comprised of 3 (or in one case, 4) redundancy Zones. Each zone in a Region has isolated power, cooling, inbound fibre, networking and control planes.
Network latency between Regions is much lower than normal internet routing and communication between Zones in the same Region is lower still.
See https://cloud.google.com/compute/docs/regions-zones and here is nice, interactive way to explore Google’s infrastructure: https://cloud.withgoogle.com/infrastructure
This makes a solid foundation for high availability. Google Cloud’s services use multiple Zones or even Regions to balance the concerns of availability, latency, throughput etc based on factors that you can influence.
So, the first point is to use multiple zones and regions in the most effective way to achieve your goals for availability.
Multi-region Database Services
Google Cloud has a variety of database services on offer, including fully managed partner solutions such as Redis Enterprise and MongoDB Atlas and builds of Open Source databases, available through the Marketplace. However for now I would like to focus on just three of GCP’s globally distributed, scalable and highly available managed database offerings that are available in multi-region configurations.

Cloud Firestore is a document NoSQL database and the successor of both Cloud Datastore and Firebase Realtime Database.
Cloud Bigtable is the wide column key-value store that sits at the heart of much of Google’s own services infrastructure supporting several multi-billion user products. Because it utilizes eventual consistency it can support I/O request latency of just a few ms even with a globally distributed cluster.
Cloud Spanner is also a critical component in many of Google’s own products. It supports standard SQL and transactional consistency on a globally distributed, synchronously replicated relational database. It is an implementation of the Paxos protocol and uses atomic clocks for precise distributed time keeping - see the official documentation or What makes Cloud Spanner tick? for more on that.
Google Kubernetes Engine (GKE)
Regional clusters
https://cloud.google.com/kubernetes-engine/docs/concepts/types-of-clusters
Google Kubernetes Engine is Google Cloud’s managed Kubernetes and Regional Clusters provide a higher SLO compared to single-zone clusters. This is because they replicate the cluster master and nodes across multiple zones in a region.
GKE as a managed service provides many benefits including:
- Automatic upgrade and repair of nodes
- Curated versions of Kubernetes and node OS
- Deep GCP integration
- The Compute Engine SLA applies to Node availability (Kubernetes data plane)
In Kubernetes, Pods are the basic unit being managed and are considered to be disposable. With GKE the underlying VM based Nodes are also considered disposable — they will be created and disposed of as needed. When you are at the peak of Kubernetes mastery, you may also like to consider entire clusters as disposable.
As a managed platform, GKE is kept up to date with security patching and is easy to stay up to date with the latest stable versions of Kubernetes — all without downtime for your workloads.
Ingress for Anthos
https://cloud.google.com/kubernetes-engine/docs/concepts/ingress-for-anthos
Ingress for Anthos provides global load balancing for multi-cluster, multi-regional environments.

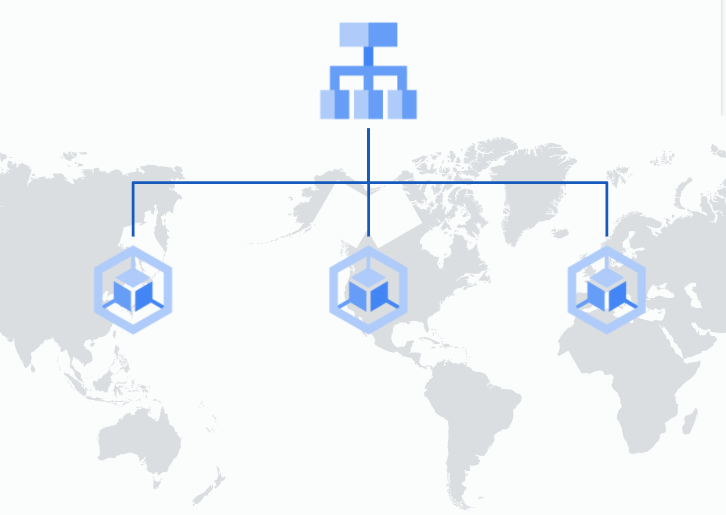
This gives you a Global HTTPS Load Balancer anycast IP address that routes clients to the cluster in the nearest available region. Target clusters can be zonal or regional:
- Zonal for lower latency
- Regional for higher availability
A highly available alternative to a regional cluster is to deploy multiple, single zone clusters across different regions. This has the advantage of simpler, lower latency clusters in each zone. This could be considered a best practice especially when using the Service Mesh platform to manage things.
Anthos Service Mesh (ASM)
Overview
https://cloud.google.com/anthos/service-mesh
A fully managed multi-cloud service mesh platform that separates applications from service networking and decouples operations from development. It provides Resiliency, Efficiency, Visibility, Traffic Control, Security and Policy Enforcement.
A service mesh abstracts the concerns of a distributed system network from the application, such that individual Services need not be not aware of the network and its topology or the policies defined on it.
The service mesh platform is also a key tool of the Services Operator or SRE for ensuring availability and stable operation of your micro-services based architecture.

Anthos Service Mesh Features include:
- Failure recovery: timeouts, circuit breakers, active health checks, and bounded retries.
- Traffic controls: dynamic request routing for A/B testing, canary deployments, and gradual rollouts
- Fault injection: inject delays & aborts under specified conditions and % limits
- Authentication: secured with mTLS
- Authorization: role-based access control (RBAC)
- Observability: integration with Cloud Logging, Cloud Monitoring, and Cloud Trace; Monitor service SLOs; Set targets for latency and availability and track your error budget.
- Load balancing: round robin, random and weighted-least-request schemes
We already talked about timeouts (fail fast), circuit breakers and canary relases in the previous post. Worth special mention is Fault Injection — this is how you verify the behavior of your system in circumstances that you hope will never happen. It is your easy and safe ticket to the world of Chaos Engineering.
https://en.wikipedia.org/wiki/Chaos_engineering
Traffic Director
https://cloud.google.com/traffic-director/docs
Traffic Director is ASM’s fully managed traffic control plane. It allows you to deploy global load balancing across clusters and virtual machine (VM) instances in multiple regions as well as to offload health checking from service proxies and configure sophisticated traffic control policies.
Traffic enters the mesh via Ingress for Anthos and then Traffic Director provides traffic routing within the mesh, including automatic cross-region overflow and failover.

{kind=link}
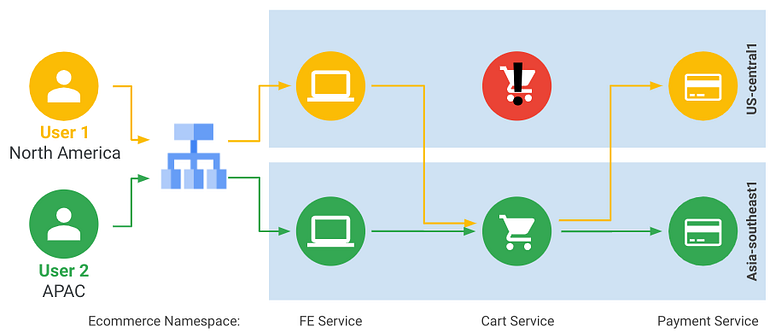
See: https://cloud.google.com/traffic-director/docs/traffic-director-concepts#global_load_balancing_with for more information and an illustration.
Traffic Director’s fine-grained and policy driven traffic management capabilities facilitate Canary Deployments that can controlled with a level of finesse not possible with Kubernetes’ standard routing.
Proxyless gRPC based Service Mesh
The Service Mesh has typically relied on the very capable and lightweight Envoy sidecar proxy, however Anthos Service Mesh now also supports proxyless service mesh based on gRPC (https://grpc.io/faq/). Less things to manage, and even lower latency are just two advantages.
https://cloud.google.com/blog/products/networking/traffic-director-supports-proxyless-grpc
Pub/Sub
https://cloud.google.com/pubsub
Pub/Sub vs Pub/Sub Lite: https://cloud.google.com/pubsub/docs/choosing-pubsub-or-lite
This is the last GCP product I will talk about in this post. There are many other interesting products that I would like to talk about but I have to stop somewhere.
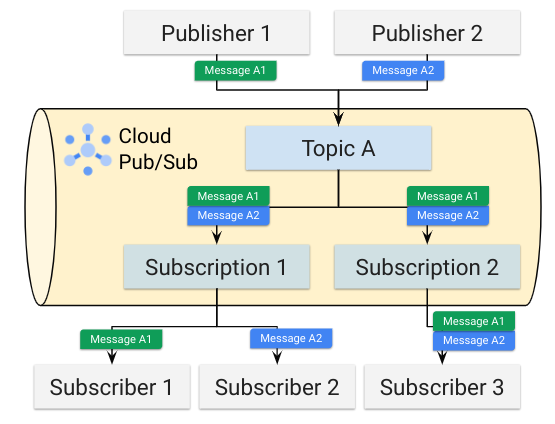
Pub/Sub is a globally distributed hyper-scale middleware infrastructure. It is an easy and robust way of implementing asynchonicity and thereby decoupling services in your architecture. This has advantages for availability especially in cases where you you just need to know that the infrastructre has accepted your message and will take care of it for you. You can subscribe to success/failure notifications or deal with failures in a separate, out-of-band process.
Cloud Pub/Sub is also effective as a buffer to smooth out peaks in high throughput traffic such as with streaming to protect more sensitive backend processing.
Conclusion
Patterns to support Reliability and Availability are built into the cloud platform at a very fundamental level. This translates to highly available cloud platform services with high SLAs/SLOs. It also raises the baseline for the level of availability that you can achieve for your use case.
The danger however is complacency. In other words, you come to rely on the availability of the underlying platform. The SRE book has an interesting story from Google’s own experience of this — search for “Chubby” to see what I mean.
There are still many architectural and design pattern choices that you need to make to take your system to the next level — the goal being able to operate uninterrupted even in the worst cases that you can imagine, such as loss of a an entire regional data center and, even more importantly, much more subtle cases that may only be detectable by looking at data aggregated over time, such as in SLO monitoring.
Do adopt the practices of SRE and Chaos Engineering and let owners and clients of your mission critical service know that you reserve the right to experiment even in production - whenever you have sufficient error budget, that is. You can convince yourself and maybe even them that this is for their own good as it will flush out brittle dependencies that will cause even more issues when real, unpredictable and difficult to resolve problems occur.
In closing, GCP is a great and cost effective platform for you to develop modern and cloud native architectures that balance the various concerns of redundancy, performance/latency and reliability/availablity according to your specific needs.
Next steps
I recommend to navigate over to the Cloud Next OnAir 2020 event site for on-demand videos and PDFs of the sessions and maybe search on availability and/or reliability and see what comes up: https://cloud.withgoogle.com/next/sf/sessions#industry-insights .
This is one of my favorites “Building Globally Scalable Services with Istio and ASM” https://cloud.withgoogle.com/next/sf/sessions?session=APP210
And this “Future-proof Your Business for Global Scale and Consistency with Cloud Spanner” https://cloud.withgoogle.com/next/sf/sessions?session=DBS204
Thanks to Yasushi Takata, Yutty Kawahara, Takahiko Sato, and Kazuu Shinohara.
No comments:
Post a Comment