August 31, 2020
Introduction
It is very hard to purchase at lowest point in the market. So I just took some risk and made purchase this morning.
TFSA Victoria portfolio







August 31, 2020
Introduction
It is very hard to purchase at lowest point in the market. So I just took some risk and made purchase this morning.
TFSA Victoria portfolio
August 31, 2020
Introduction
It is hard for me to lose weight since I am busy working with algorithms and investment. I went out running one hour in Burnaby central middle school from 10:30 AM to 11:30 AM. But I was so exhausted, I need to figure out how to set highest priority to be a runner again, in my 53 year old age, 192 lb weight.
Being a runner
I plan to attend the running race. Here is the webpage about the race.
August 31, 2020
I like to figure out why I am not rich. I do not try hard enough. That is a lot of opportunities for me to learn, but I just made so many simple mistakes and then failed to build wealth.
Case study
I do think that most important is to have confidence. To stay in United States or Canada, I do not build wealth enough for me to live comfortably, from 1996 to 2010 in USA, Florida; from 2010 to 2020 in Vancouver, Canada.
I like to figure out how many case studies I can think about and then work on improvements.
Finance illiteracy is most biggest one. But I also find my weakness in my personality. I have to think more carefully about time I have and my priority in my life.
Being single is not so terrible and I do enjoy so many things. I have to work on my confidence in terms of choosing friends, being independent, and also continuously learning.
August 31, 2020
It is my understanding for Willingdom church small group activities. Best communication should be face-to-face or phone conversation. Not using wechat, typing. Personal life and work experience is most helpful for others to learn from. Today I got a phone call from my SJTU 1984 to 1998 classmate from different major.
I tried to maintain close relationship for investment group. So I also try to limit the number of people in the group. It is hard for us to break ice and get face-to-face communications. I tried a few times this month, but I failed a few times. Specially when I failed to make purchase of $45,000 dollars Canadian dollars on Canadian oil stocks on August 24, 2020.
I got invitation from my friend in investment group, she called me and we talked over one hour. This is the third or fourth call we had together. I am a beginner as a stock investor, she has more experience than me. She told me that she made over $10,000 gains in August 2020. She has 10 - 12% return on her investment portfolio.
Last time when we talked, she said that she did not think Facebook could do much better than others, from June 5 to August 30, Facebook has 30% return.
We cannot beat the market. But at least we are learning to work together, and share tips how to understand business, what to invest and figure out what are best for us to learn.
Stock purchases:
CCL, BA, INTC, SAVE, BAC, YINN
Here is the link.
August 30, 2020
889. Construct Binary Tree from Preorder and Postorder Traversal
Introduction
I like to learn all ideas to solve this tree algorithm. I came cross this idea from the discussion post here.
The idea is to construct binary tree using preorder traversal list, so it is easy to figure out the order of nodes in preorder list is from root node to left child until last one without left child. And then it is time to set up a node as a right child.
Case study
I like to draw the diagram to explain how to solve this question using given example in the problem statement.
Input: pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1]
Output: [1,2,3,4,5,6,7]
I debugged the code and then figured out the idea. It is to construct binary tree using preorder list first, starting from root node, and then go left continuously until it is the node without left child. Actually it is the first node in postorder traveral.
Using the example, root node 1 -> left child - node 2 -> left child - node 4, argue that it is the node without left child, since value is the first node in postorder traversal, marking using a in the following diagram. Preorder traversal list is iterated from a to b to c, the third node is with value 4. Now need to increment postorder traversal list's index.
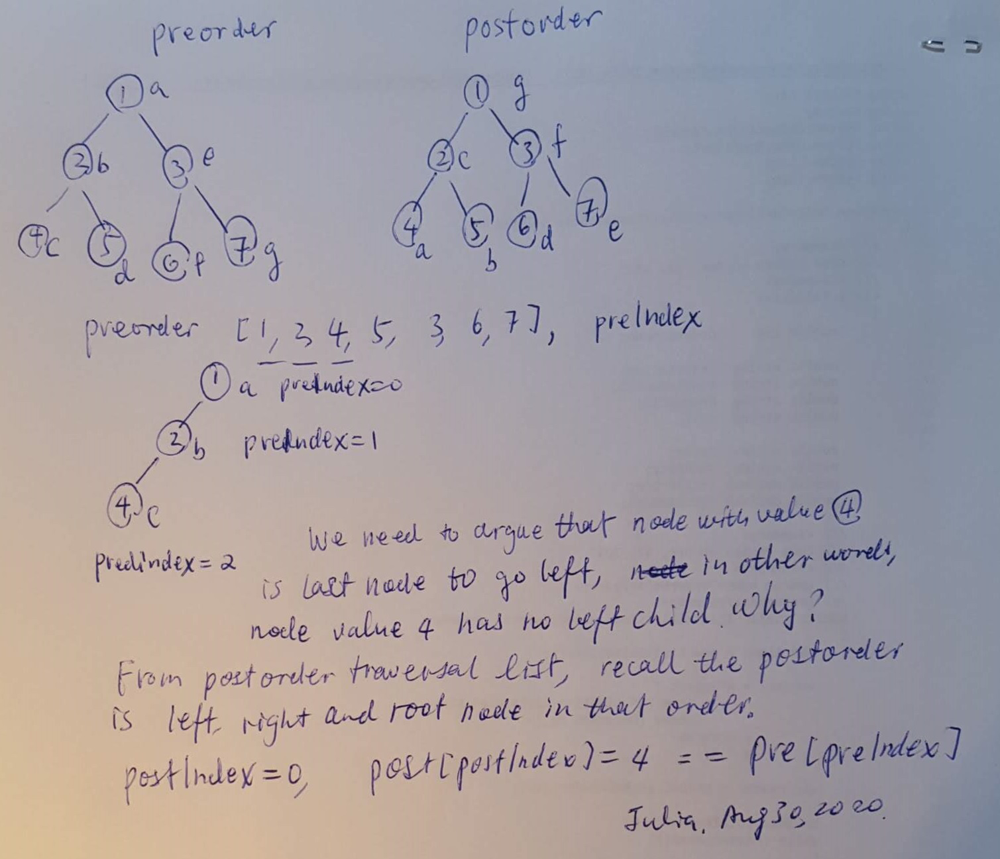
One important task is to argue that when pre[preIndex] == post[postIndex], for example, preIndex = 2, node with value 4 is leaf node, in other words, skip steps to add left and right child.
I think that the idea is hard to figure out and I will come back later to see if I can learn better next time.
Design concern
I do think that it is easy to figure out that each time a node is visited in preorder list, the node is added to the binary tree, preIndex variable is incremented by one. And if pre[preIndex] == post[postIndex], then skip to add left or right child, increment postIndex by one.
As long as preIndex and postIndex both have places to increment one, the design is completed. Do not overthink.
Time complexity
It should be O(N).
/**
* Definition for a binary tree node.
* public class TreeNode {
* public int val;
* public TreeNode left;
* public TreeNode right;
* public TreeNode(int val=0, TreeNode left=null, TreeNode right=null) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
public class Solution {
public static int preIndex;
public static int postIndex;
public TreeNode ConstructFromPrePost(int[] pre, int[] post) {
preIndex = 0;
postIndex = 0;
return runPreorder(pre, post);
}
private TreeNode runPreorder(int[] pre, int[] post)
{
var preLength = pre.Length;
var postLength = post.Length;
if(pre == null || post == null || preIndex >= preLength || postIndex >= postLength)
return null;
var rootVal = pre[preIndex];
var root = new TreeNode(pre[preIndex]);
preIndex++;
if(rootVal != post[postIndex])
{
root.left = runPreorder(pre, post);
}
if(rootVal != post[postIndex])
{
root.right = runPreorder(pre, post);
}
postIndex++;
return root;
}
}VTSMX
August 1, 2020 80.54
August 28, 86.43
Gains: 5.89/80.54 = 7.31%
Here is the link.
GAP store - pivot to online sales
CNBC's Bertha Coombs on Gap earnings. And Delano Saporu, New Street Advisors founder, on where the stock is headed. With CNBC's Melissa Lee and the Fast Money traders, Guy Adami, Tim Seymour, Karen Finerman and Steve Grasso. For access to live and exclusive video from CNBC subscribe to CNBC PRO: https://cnb.cx/2NGeIvi
August 29, 2020
It is too ambitious as a beginner to invest on stock market. But I like to make plans, and act on my goal. How can I invest on stocks and then make $10,000 dollars in Sept. 2020. What are those ideas I can examine and make sure that it might help in my ability as a equity research beginner - from March to August less than six months experience.
I did one good purchase on July 31, 2020. I noticed that I was too worry about market crash and SPX went would go down below 3000. So I did make purchase Canadian oil stock and made over $3000 Canadian dollars gains in less than one week.
But I did not make it happen on August 24, 2020. President Trump gave news conference in the weekend, and I made plans for purchase. But I was still not able to make it. Investment is hard than I think.
I changed my target from $10,000 Canadian dollars to $3000 dollars. I like to take less risk since I am a beginner. I do not know too much about risks in market.
Here are 10 ideas to think about.
August 29, 2020
Introduction
It is hard for me to get into Facebook and work on challenge job as a software engineer. I need to think about investing FB stock as early as January 2015 when I had first one hour onsite interview on Westin hotel.
June 5, 2020
I did read the article about Facebook will double in next 12 month. From June 5 to August 29, the gains are 30% increase.

I got a phone call from Facebook recruiter and then I was invited to apply again for the job. I should invest FB stock starting from June 5, 2020.
Now it is 30% more market value. $293.66/ share.
August 30, 2020 9:58AM
I should take some actions if I do believe that Facebook is such a great company, and I should work on FB stock investment as early as possible.
Here is the link.
Paul Allen McCulley (born March 13, 1957)[1] is an American economist and former managing director at PIMCO. He coined the terms "Minsky moment" and "shadow banking system", which became famous during the Financial crisis of 2007–2009. He is currently a senior fellow at Cornell Law School and an adjunct professor at Georgetown McDonough School of Business.
Here is the link.
Ray Dalio is the original founder and former CEO of Bridgewater Associates, which is currently the largest hedge fund in the world. He's known for his macro economic expertise, and as the pioneer of risky parity investing, a investment strategy that focuses on diversifying according to risk rather than asset class. In a recent interview released by Bridgewater Associates, Ray Dalio talks about the current state of the economy and what is to come. Ray Dalio explains the different types of monetary policy used in the past, present, and what will likely be done in the future. He then shares his opinion on the markets, and provides investors with some ideas for investing in the coming months and years. If you're worried about market volatility or a full on market crash, this is an interview you don't want to miss. Ray Dalio is a true genius inside and outside of the investment world, and his insights on the stock market, equities, bonds, cash, and gold is unlike anyone else in the mainstream financial media.
CNK stock went up from August 24 to August 28
August 24 - 12.39
August 28 - 15.26
over 20% return in less than one week.
Here is the link.
June 19, 2020: The coronavirus has accelerated a new paradigm of coordinated monetary and fiscal policy where central banks are printing money to finance large budget deficits and spark spending. Senior Portfolio Strategist Jim Haskel and co-CIO Ray Dalio explore why the by-product—zero or near-zero interest rates across the developed world—is a critical issue for investors to understand and how similar moments in history can provide valuable lessons to navigate volatility.
Here is the link.
Aug.28 -- One of the most iconic brands in financial television returns for today's issues and today's world. This week's Wall Street Week features David Westin's interviews with Commerce Secretary Wilbur Ross, Energy Secretary Dan Brouillette, Home Depot Co-Founder Ken Langone, Former SBA Administrator Linda McMahon, and Former Oklahoma Governor Frank Keating. The conversations analyze President Trumps's economic, health care, energy and trade policies. Former Treasury Secretary Lawrence H. Summers and Former Council of Economic Advisers Chair Glenn Hubbard debate what Biden and Pres. Trump's policies will mean for an economy that is dealing with a pandemic.
Here is the link.
"I think Abbott's come up with a game changer, here,' the "Mad Money" host said. Subscribe to CNBC PRO for access to investor and analyst insights: https://cnb.cx/2Vtntx6 Investors turned bullish on the recovery theme Thursday, thanks to big news on the coronavirus testing front, CNBC’s Jim Cramer said. “The recovery plays got a huge boost last night when Abbott Laboratories announced a 15-minute Covid test with great reliability that you can take at home,” the “Mad Money” host said. Abbott Labs, a medical supplies manufacturer, announced Wednesday evening that it received emergency use authorization from the U.S. Food and Drug Administration for a rapid Covid-19 test that can cost $5. The company plans to begin shipping tests out in September and expects to produce 50 million tests per month by October. The test, BinaxNOW, which is supported by a mobile application to display results, is expected to be used in work and school environments, which is seen as critical in the fight to contain coronavirus and fully reopen the U.S. economy. The White House plans to buy 150 million of the tests in a $750 million deal with the device maker. Abbott Labs shares popped 8% on the news, closing at a record $111.29. “I think Abbott’s come up with a game changer here,” Cramer said. The comments come after equities markets turned in a mixed day of trading. The Dow Jones Industrial Average, which poked its head into positive territory before ducking back under in a volatile session, rose 160 points to 28,492.27 for a 0.57% gain. The S&P 500 advanced 0.17% to a new closing high of 3,484.55. The tech-heavy Nasdaq Composite snapped a five-day winning streak when it slipped 0.34% to 11,625.34. Abbott Labs was among the top gainers in Thursday’s market, flanked by big gains in travel and entertainment stocks. Live Nation saw the biggest advance in its shares, rallying almost 9% to a $57.26 close. The cruise and airline stocks of Royal Caribbean, Norwegian, United Airlines and Carnival rounded out the top 5 on the S&P 500 during the trading day. “If you know your fellow passengers don’t have the virus, you’d be a lot more willing to fly or book a cruise,” Cramer said. The other end of the index was peppered with what’s been dubbed the stay-at-home plays, or companies that benefit from a lockdown environment, especially in the travel, leisure and financial industries. Among the biggest decliners were Netflix, Facebook, Adobe and Lowe’s.
August 29, 2020
It is so surprising to learn that VOO ETF has 10% return from August 1 to August 29, 2020. 10% return for one month, I just could not believe that.
I remembered that I bet on July 31, 2020 over $30,000 Canadian dollars to purchase Canada oil stocks, I bet that market will not crash and go below SPX 3000. Right now SPX is around 3500.
I did not purchase VFV.TO using my TFSA account, and all my cash does not generate return from August 5 to August 29.
I did not make plan to purchase oil stocks around August 24, 2020. But I did not enter those order in time.
VFV.TO price July 31, 2020 - $77.50
August 29, 2020 - $81.70
August 29, 2020
Introduction
It is so surprising to learn that VOO ETF has 10% return from August 1 to August 29, 2020. 10% return for one month, I just could not believe that.
July 31, 2020
I remembered that I bet on July 31, 2020 over $30,000 Canadian dollars to purchase Canada oil stocks, I bet that market will not crash and go below SPX 3000. Right now SPX is around 3500.
I did not purchase VFV.TO using my TFSA account, and all my cash does not generate return from August 5 to August 29.
I did not make plan to purchase oil stocks around August 24, 2020. But I did not enter those order in time.
VOO.ETF
July 31, 2020 $297.01
August 29, 2020 $321.00
August 29, 2020
It is Saturday afternoon. I like to think about my plan to spend Saturday evening. I like to think about my career, and one of ideas is to write some code on leetcode.com.
Weekend is my time
I like to find something to write. Tree algorithm is my favorite. I like to work on coding for a few hours this evening.
I came cross Linkedin profile of Dr. Dan Wu, since I followed her on Linkedin.com. I spent 10 minutes to read about her advisor prof. Barry Boehm.
I like to think about what makes a person so successful in her study and career. Education, advisor, university education and all other things related to hard work.
I also read so many managers' profile on linkedin.com. It is such great time for engineers in computer science last 10 years.
August 29, 2020
It is my plan to learn how to make more money in order to find a place to purchase in the city of Surrey. The price of condo goes down below $300,000 dollars, but I like to learn how to invest on stock market first and think about being a good learner how to understand business works. Life is much better to learn so many things go on in the world, Trump hotel filed bankrupt in the city of Vancouver. I like to talk about my concern about home ownership in Canada from 2010 to 2020.
I found out that I could not do very well in USA from 1999 to 2001 in my personal finance. And then later on I did not do very well from 2006 to 2007. Those 10 year struggle in United States taught me so many lessons as a single person who has Christian belief.
I worried about home ownership to have over $150,000 dollars mortgage back from 2010 to 2012 if I take a mortgage. I worried about my Canada citizenship application. How can I make a living without a citizenship in Canada? How can I make my job much easy to handle?
I did not take risk to purchase a condo in British Columbia. And I lost directions, shopping trips to USA Bellingham, and vacations back to China almost every year.
The condo price went up after 2016, and it is impossible for me to get the loan to afford one bedroom condo in the city of Surrey.
From 2010 to 2012, I had home equity loan around $38,000 US dollars in United States, and I did not feel so comfortable to take another $150,000 Canadian dollar mortgage at that time.
August 29, 2020
It is possible to reach $10,000 dollars gains in stock market investment return. I do not learn how to invest passively from 1999 to 2001, and then 2007. I left all my IRA and 401 K in money market fund from 2010 to 2019, with less than 1.5% annual return with over $26,000 dollars investment called 401 K or IRA. Now my goal is to reach first $10,000 dollars gains as an active investor after market crash in March 2020.
I thought about so many mistakes I have made as I started to learn and invest on stocks by myself this March 27, 2020.
I learned from OVV.TO stocks, I only purchased 200 shares on March 27, 2020 and then struggled on my hay fever, and then worked full time, and OVV just went up 300% in less than two months. I learned the power of stock market.
I thought that stock investment should not be that difficult. I invested $13,000 US dollars on June 5, 2020, and then took the loss of $3000 dollars, and understood that market is so volatile.
I thought about why I could not purchase $100,000 dollars on OVV stock on March 27, 2020. I worried about so many things, my job, my further loss of capital of investment, and my hay fever; I was lucky to learn that $4000 to $5000 rebound is so quick and easy, it is better for me to take some risk to play some stocks. Those OVV.TO stock lost 90% of value, it is ok if I lose all those 200 shares of investment, less than $700 dollars.
I have to push myself to work on $10,000 dollars gains first. Now I have $800 dollars gains on Ameritrade.com retirement account, $5,500 dollars gains on TFSA account.
I have to figure out how to make another $3700 dollars gains in next two months.
I like to build wealth step by step. First I should learn how to build wealth the first $10,000 dollars on stock market first.
August 29, 2020
Introduction
It is tough for me to build wealth and make million dollars on my career, from salary and bonus. I have to understand that I am living in frugal life style but I still struggle to make a living as a software programmer.
10 reasons I like to invest on stock market
I like to put together 10 reasons I like to invest on stock market. I will come back to revisit again, and add more content.
August 29, 2020
It is hard for me to learn how to invest. I have to learn how to make decision when to purchase and when to sell. I act by my own understanding, and then I try to learn from others. I start to write lessons I learn after I sold 800 shares of ENBL, and other topics as well.
90% of investors do not make money as an active investor, only 10% of them make money. I am pretty sure that I am the beginner of investor, after I worked on passive investment, I quickly made purchase at highest position SPX 3500 on June 5, 2020, I lost $3000 gains from May 2019 to 2010 June 5, specially after March market crashes and rebound.
I started to learn about business, stocks, and things I should know about stock price, volatile of stock price.
I have to push myself to learn more things about business. It is tough but I like to learn and see if I can build some wealth from stock market.
My Ameritrade.com stock account now has $800 dollars gains from April 2019, and my Canada TFSA account has around $5000 dollars gains so far.
It is not easy to learn and I have invested over hundreds of hours on those portfolios.
Here is the link.
Signs of weakness
1. Downside reversal
2. Stalling
3. Churning
Downside reversal
August 29, 2020
Introduction
I like to spend time to look into real estate market, and then see how the market do considering coronavirus and a lot of job losses.
$20,000 maximum price drop
I do think that condo is too expensive to purchase. I came to Canada in April, 2010. At that time, one bedroom condo brand new is around $150,000 dollars in the city of Surrey near skytrain station. At that time, 1 Canadian dollars is worthy of 1 US dollars. Now it is 25% less.
The price of 1 bedroom condo price went up from 2010 $150,000 to over $300,000 dollars. Now it is around $300,000 dollars.
Here is the link.
Ken Shreve, Senior Market Writer, and Justin Nielsen, Market Research Director, share key selling strategies and show you current examples of how these techniques can boost your portfolio profits.
August 29, 2020
Introduction
I am a beginner as a stock investor, I do like to case study my own purchase and sale of ENBL stock 800 shares. ENBL stock price is $5.9 dollars, I sold 800 shares of ENBL with price 5.0, I missed 800 dollars gain. I held over two months. What is wrong? I like to work on a case study.
Case study
Here is my Ameritrade.com ENBL transaction history.



August 29, 2020
It is important for me to learn something along the way to invest on WDC stock. I learned from ENBL since I missed 800 shares for each share $1.00 dollars gains after I sold it. So after near one month, I sold 100 shares of WDC after it rebounded. I need to get back.
WDC 50 day average
Yahoo->Finance->Chart
indicators->Moving average ->50 days
Candle -> show gains or losses using candle
I learned the video talking about 40 day average. I also used Yahoo -> Finance -> chart -> 50 day average, WDC stock has $40.00 50 day average.

I like to take loss of $100 dollars to purchase back those 100 shares of WDC.

Here is the link.
O'Neil Portfolio Manager Mike Webster and MarketSmith Product Coach Irusha Peiris share their insights on early buy and sell signals you can use to lower your average cost and improves your profits.
Here is the link.
Learn to profit from the cup with handle, one of the three most common patterns top stocks form. Investor’s Business Daily has been helping people invest smarter results by providing exclusive stock lists, investing data, stock market research, education and the latest financial and business news to help investors make more money in the stock market.
Here is the link.
August 26, 2020
889. Construct Binary Tree from Preorder and Postorder Traversal
Introduction
I like to review my practice in 2018. The idea is to find left subtree's end position using two hashset comparison. The time complexity is not optimal, and it slows down the time complexity to O(n*n).
Case study
Input: pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1]
Output: [1,2,3,4,5,6,7]
The prerorder traversal [1, 2, 4, 5, 3, 6, 7], so first node is root node, and left subtree starts from index = 1 if there is one, 2 should be left subtree root value, and it's position is index = 2, last node in post order traversal. [4,5,2] is left subtree in post order.
It is better to find the left subtree's root in post order list using a hashmap with O(1) time complexity.
/**
* Definition for a binary tree node.
* public class TreeNode {
* public int val;
* public TreeNode left;
* public TreeNode right;
* public TreeNode(int x) { val = x; }
* }
*/
public class Solution {
public TreeNode ConstructFromPrePost(int[] pre, int[] post)
{
if (pre == null || post == null)
return null;
if (pre.Length != post.Length)
return null;
var length = pre.Length;
return constructTree(pre, 0, length, post, 0);
}
/// <summary>
/// based on the tree has distinct value for each node, left subtree can be determined by
/// comparison pre and post array subset.
/// </summary>
/// <param name="pre"></param>
/// <param name="start1"></param>
/// <param name="end1"></param>
/// <param name="post"></param>
/// <param name="start2"></param>
/// <param name="end2"></param>
/// <returns></returns>
private static TreeNode constructTree(int[] pre, int start1, int length, int[] post, int start2)
{
if (start1 >= pre.Length || length == 0) // caught by online judge
return null;
if (length == 1)
{
return new TreeNode(pre[start1]);
}
var root = new TreeNode(pre[start1]);
var setPre = new HashSet<int>();
var setPost = new HashSet<int>();
// Find left subtree
int index = 0;
while (index < length)
{
setPre.Add(pre[start1 + 1 + index]); // caught by online judge, + 1, skip the root
setPost.Add(post[start2 + index]);
if (setPre.IsSubsetOf(setPost) && setPost.IsSubsetOf(setPre))
{
break;
}
index++;
}
var leftSubtreeLength = index + 1;
var rightSubtreeLength = length - leftSubtreeLength - 1;
root.left = constructTree(pre, start1 + 1, leftSubtreeLength, post, start2);
root.right = constructTree(pre, start1 + 1 + leftSubtreeLength, rightSubtreeLength, post, start2 + leftSubtreeLength);
return root;
}
}Here is the link.
August 28, 2020
Introduction
It is important to write a solution using optimal time complexity. Put inorder traversal list into a hashmap since all nodes have distinct value, so it takes O(1) time to find root node's index in inorder traversal list.
/**
* Definition for a binary tree node.
* public class TreeNode {
* public int val;
* public TreeNode left;
* public TreeNode right;
* public TreeNode(int val=0, TreeNode left=null, TreeNode right=null) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
public class Solution {
/// <summary>
/// August 28, 2020
/// The idea is to put inorder traversal list into a hashmap, so lookup can be O(1) time complexity;
/// Just apply recursive function to solve the problem, each time the root node can be found
/// from the first node in preorder traversal list.
/// </summary>
/// <param name="preorder"></param>
/// <param name="inorder"></param>
/// <returns></returns>
public TreeNode BuildTree(int[] preorder, int[] inorder)
{
if (preorder == null || inorder == null || preorder.Length != inorder.Length ||
preorder.Length == 0)
{
return null;
}
var map = new Dictionary<int, int>();
var inLength = inorder.Length;
for (int i = 0; i < inLength; i++)
{
map.Add(inorder[i], i);
}
return runHelper(preorder, 0, preorder.Length - 1, inorder, 0, inorder.Length - 1, map);
}
/// <summary>
/// Recursive function, each step one node is solved in binary tree
/// </summary>
/// <param name="preorder"></param>
/// <param name="preStart"></param>
/// <param name="preEnd"></param>
/// <param name="inorder"></param>
/// <param name="inStart"></param>
/// <param name="inEnd"></param>
/// <param name="map"></param>
/// <returns></returns>
private TreeNode runHelper(int[] preorder, int preStart, int preEnd,
int[] inorder, int inStart, int inEnd, Dictionary<int, int> map)
{
if (preStart > preEnd)
{
return null;
}
var rootValue = preorder[preStart];
var root = new TreeNode(rootValue);
var rootIndex = map[rootValue];
// calculate left subtree's length using inorder list
var leftSubTree = rootIndex - inStart;
var rightSubTree = inEnd - rootIndex;
root.left = runHelper(preorder, preStart + 1, preStart + leftSubTree,
inorder, inStart, inStart + leftSubTree - 1, map);
root.right = runHelper(preorder, preStart + leftSubTree + 1, preEnd,
inorder, rootIndex + 1, inEnd, map);
return root;
}
}Here is the link.
How can you tell if a stock you're thinking about buying is outperforming the market? One quick and easy way is by looking at the relative strength line, a key technical indicator. So if you're just starting to learn how to read stock charts, you'll want to pay attention to this. A good stock chart will give you an indicator that you can use to help confirm your buying decisions -- the relative strength line. ((Take a look at this chart from IBD’s MarketSmith service.)) The relative strength line is the blue line on the chart. It measures a stock’s price performance versus the S&P 500, which is often used to represent the overall market. So if you’re comparing a stock’s price move to that of the S&P 500, that can help you determine whether or not the stock you’re thinking about buying is showing outperformance. If the relative strength line is trending down, it tells you the stock is lagging the overall market. But, if the relative strength line is trending higher, that means the stock is outperforming the market. Furthermore, if the line is spiking to a new high, that’s bullish. What’s even more bullish is if the relative strength line is at a new all-time high before the stock’s price reaches a new all-time high. When a stock is breaking out and entering a buy area, seeing the relative strength line at a new high is a positive confirmation. So just like you want to see heavy volume on a breakout, as well as the stock closing in the top half of its trading range, another bullish indicator is the relative strength line at a new high. This chart also has a Relative Price Strength Rating next to the relative strength line, which is a little different. While the relative strength line compares a stock’s performance to the S&P 500, the Relative Strength Rating calculated by Investor’s Business Daily measures a stock’s price performance compared to all the other stocks in our database. With 1 being the lowest and 99 the highest, think about these ratings like grades on an exam. A 90 or higher is especially positive. The takeaway here: buy stocks that are outperforming the market, because that will increase your chances of scoring big gains. Make sure to check out investors.com and MarketSmith, where you can find screens for stocks with relative strength lines at new highs. And at investors.com/howtoinvest we have a detailed education on how to invest in stocks. Learning how to invest in stocks is an important first step to building wealth. But where do you start? How do you buy stocks? How do you know when to sell stocks? Do you really need to know how to read stock charts? You'll find the answers to all those questions as we continue to add new How To Invest videos to this page. How To Start Investing In Stocks Before you start investing in stocks, it's important to learn how the stock market works and understand some basic rules about how to buy stocks and when to sell stocks. At Investor's Business Daily, you'll find a time-tested investing strategy known as the CAN SLIM Investing System. Developed from our unique study of every market cycle since the 1880s, the CAN SLIM system identifies the seven common traits of winning stocks. And the videos below will show you how to apply various aspects of the CAN SLIM strategy. Be sure to subscribe and keep coming back, as we'll be adding new How To Invest videos on chart patterns, buying and selling and more topics in the days and weeks ahead. Investor’s Business Daily has been helping people invest smarter results by providing exclusive stock lists, investing data, stock market research, education and the latest financial and business news to help investors make more money in the stock market.
Here is the link.
Now that you know why it's important to use stock charts and the basics contents of charts, there are three key concepts you need to familiarize yourself with in order to spot profitable chart patterns. Once you can analyze stock charts using these key clues, you'll be ready to start buying stocks. Once you know why it’s important to use stock charts and the basics of what’s in a chart, let’s put it all together and discuss the three telltale clues to look for when analyzing stock charts. After you familiarize yourself with these three key concepts, you’ll be ready to spot profitable chart patterns — those are the launching pads that kick off virtually all major stock moves. Clue #1: What’s the trend? With just a quick glance at a weekly chart, you can see if the stock’s in an uptrend, a downtrend or just trading essentially sideways. You only want to buy a stock when it’s already moving in the right direction, and that’s up. There’s no need to take the risk of buying a stock that’s clearly heading south. Wait until the stock can prove its strength by rebounding into an uptrend. And when a stock is trading sideways, there’s no clear trend. Again, reduce your risk by waiting for a new uptrend to begin before you buy. Clue #2: What “story” is the price and volume action telling? Charts show you if a stock is being heavily bought or sold by fund managers and other large investors. This is super crucial because it’s these large institutional investors that have the power to push a stock higher…or lower. Figuring out what the large investors are up to is easy. All you need to do is check the price and volume action in the chart. These big investors are managing so much money that they’re too big to hide what they’re doing. So you can literally see what they’re doing by looking for unusual spikes in volume. Think of it this way: when the stock price is up significantly and the number of shares traded is well above average, that tells you fund managers and other large investors are heavily buying. On the flip side, when the stock is down significantly in unusually heavy volume, that shows you fund managers are aggressively selling or getting rid of the stock. Long story short, always check the volume when looking at any changes in share price. That will tell you how serious the buying or selling actually is. Clue #3: Is the stock finding support…or hitting resistance? Think of this like a floor of support or a ceiling of resistance. When a stock pulls back, you really want to see if finds support at key areas, such as a moving average line, a prior buy point or even sometimes a round number in the stock’s price. Look at Nvidia’s chart starting back in 2016, and see how it found support at the 10-week line along its big run. If the stock does find support, it means large investors are stepping in to support the stock. That can be a sign to hold or even add shares to your position if the stock rebounds higher from that support level. But if the stock fails to find that support and crashes right through a moving average, like the 10-week line in heavy volume, that’s often a trigger to sell. It means fund managers are now aggressively dumping shares. The concept of resistance is especially key when it comes to spotting the best time to buy a stock. After a stock forms a floor of support and begins to climb higher, it’ll eventually come up against a ceiling of resistance. That’s a key testing ground: Will it punch through that ceiling in heavy volume? Or will it simply bump its head and come back down? The best time to buy is when the stock proves its strength by punching through a former line of resistance in strong volume — we’ll get more into that later. But all in all, when you’re looking at a stock chart, start by checking these three telltale clues. Doing that will give you invaluable insight into the health and outlook of that stock. Investor’s Business Daily has been helping people invest smarter results by providing exclusive stock lists, investing data, stock market research, education and the latest financial and business news to help investors make more money in the stock market.
Here is the link.
Moving averages are a crucial component of how to read stock charts. We'll show you how looking at these trend lines can cut through the noise of daily chart action and give you a clearer picture of what's happening.
One handy way to figure out if a stock is on a roll is to look at its moving averages, which track the average closing share price over a certain period of time. Why look at these trend lines? Well, for one thing, they cut through the noise of daily chart action and can give you a clearer picture of what’s happening. The 50-day moving average is the red line on this chart. If it’s climbing upward, that means the stock is trending higher – always a good a sign. 200-day moving average: the average share price over the last 200 days of trading. It’s also a fine way to figure out where the big money is moving. Institutional investors often use the 50-day line as a reference point, buying more shares when a stock pulls back to the moving average. And when shares rebound higher off the key level as a result, we call that “finding support.” Why is that important? Because those brief pullbacks can lead to additional buying opportunities for individual investors like you. On the flip side, when a stock crumbles below a moving average in heavy volume, we call that “breaking support.” And when a stock has trouble getting back above that line, we call that “hitting resistance.” And that might mean that the big investors aren’t as interested in the stock as they used to be. As always, make sure you’re keeping an eye on volume, because that’s how you know just how aggressively fund managers and other major players are moving into or out of a stock.Here is the link.
Finding top-performing stocks doesn't have to mean a tradeoff with environmental, social and governance values. Microsoft and Edwards Lifesciences are two top stocks that made IBD's just-released ESG 50 list. Their strong fundamentals and ESG initiatives show up in the chart action. Investor’s Business Daily has been helping people invest smarter results by providing exclusive stock lists, investing data, stock market research, education and the latest financial and business news to help investors make more money in the stock market.
These are just some of the reasons I addressed money in my new Girl Boner book and forthcoming journal and why I was thrilled to sit down with Elaine Low on Girl Boner Radio recently. The financial journalist and video producer for Investor’s Business Daily had a lot to say about missing conversations around money, the gender gap in terms of investing and practical ways we can all start empowering ourselves financially.
It's tough to talk about money and share salary info or investing and saving habits. But it's something that can help to build independence, as well as confidence in ourselves and our ability to reach our goals.
- Elaine Low